- 关于MogDB
- 快速入门
- 特性描述
- 概览
- 高性能
- 高可用
- 维护性
- 兼容性
- 视图增加%rowtype属性
- 聚合函数distinct性能优化
- 聚合函数支持KEEP子句
- 聚合函数支持场景扩展
- 兼容支持MySQL别名支持单引号
- 支持current_date/current_time关键字作为字段名
- 自定义type数组
- For Update支持外连接
- MogDB支持Insert All特性
- Oracle DBLink语法兼容
- 创建PACKAGE/FUNCTION/PROCEDURE时去除TYPE类型转换提示
- 支持MERGE INTO命中索引时使用Bypass方法
- 支持增加存储过程及函数参数的nocopy属性
- 支持在数组extend的参数中传入数组的count属性
- 支持q quote转义字符
- 支持两个date类型的数据相减返回numeric类型
- 支持表函数table()
- 支持PROCEDURE/FUNCTION/PACKAGE的end后的name和Oracle保持一致
- 支持WHERE CURRENT OF写法
- 支持包内常量作为函数或者过程入参的默认值
- 支持PLPGSQL subtype
- 支持无参数FUNCTION的同义词调用不加括号
- 支持dbms_utility.format_error_backtrace
- 支持PIVOT和UNPIVOT语法
- mod函数兼容
- 支持聚集函数嵌套
- ORDER BY/GROUP BY场景兼容
- 支持在建表后修改表日志属性
- INSERT支持ON CONFLICT子句
- 支持AUTHID CURRENT_USER
- PBE模式支持存储过程out出参
- 数据库安全
- 企业级特性
- 应用开发接口
- AI能力
- 中间件
- 负载管理
- 安装指南
- 升级指南
- 管理指南
- 高可用指南
- AI特性指南
- 安全指南
- 开发者指南
- 应用程序开发教程
- 开发规范
- 基于JDBC开发
- JDBC包、驱动类和环境类
- 开发流程
- 加载驱动
- 连接数据库
- 连接数据库(以SSL方式)
- 连接数据库(UDS方式)
- 执行SQL语句
- 处理结果集
- 关闭连接
- 日志管理
- 示例:常用操作
- 示例:重新执行应用SQL
- 示例:通过本地文件导入导出数据
- 示例:从MY向MogDB进行数据迁移
- 示例:逻辑复制代码示例
- 示例:不同场景下连接数据库参数配置
- 示例:jdbc主备集群负载均衡
- JDBC接口参考
- java.sql.Connection
- java.sql.CallableStatement
- java.sql.DatabaseMetaData
- java.sql.Driver
- java.sql.PreparedStatement
- java.sql.ResultSet
- java.sql.ResultSetMetaData
- java.sql.Statement
- javax.sql.ConnectionPoolDataSource
- javax.sql.DataSource
- javax.sql.PooledConnection
- javax.naming.Context
- javax.naming.spi.InitialContextFactory
- CopyManager
- JDBC常用参数参考
- JDBC发布记录
- 基于ODBC开发
- 基于libpq开发
- 基于Psycopg2开发
- 基于.NET开发
- 基于MogOCI开发
- 调试
- 存储过程
- 用户自定义函数
- PL/pgSQL-SQL过程语言
- 定时任务
- 自治事务
- 逻辑复制
- Extension
- MySQL兼容性说明
- Dolphin Extension
- Dolphin概述
- Dolphin安装
- Dolphin限制
- Dolphin语法介绍
- SQL参考
- 关键字
- 数据类型
- 函数和操作符
- 表达式
- DDL语法一览表
- DML语法一览表
- DCL语法一览表
- SQL语法
- ALTER DATABASE
- ALTER FUNCTION
- ALTER PROCEDURE
- ALTER SERVER
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLESPACE
- ALTER VIEW
- ANALYZE | ANALYSE
- AST
- CHECKSUM TABLE
- CREATE DATABASE
- CREATE FUNCTION
- CREATE INDEX
- CREATE PROCEDURE
- CREATE SERVER
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLESPACE
- CREATE TRIGGER
- CREATE VIEW
- DESCRIBE TABLE
- DO
- DROP DATABASE
- DROP INDEX
- DROP TABLESPACE
- EXECUTE
- EXPLAIN
- FLUSH BINARY LOGS
- GRANT
- GRANT/REVOKE PROXY
- INSERT
- KILL
- LOAD DATA
- OPTIMIZE TABLE
- PREPARE
- RENAME TABLE
- RENAME USER
- REVOKE
- SELECT
- SELECT HINT
- SET CHARSET
- SET PASSWORD
- SHOW CHARACTER SET
- SHOW COLLATION
- SHOW COLUMNS
- SHOW CREATE DATABASE
- SHOW CREATE FUNCTION
- SHOW CREATE PROCEDURE
- SHOW CREATE TABLE
- SHOW CREATE TRIGGER
- SHOW CREATE VIEW
- SHOW DATABASES
- SHOW FUNCTION STATUS
- SHOW GRANTS
- SHOW INDEX
- SHOW MASTER STATUS
- SHOW PLUGINS
- SHOW PRIVILEGES
- SHOW PROCEDURE STATUS
- SHOW PROCESSLIST
- SHOW SLAVE HOSTS
- SHOW STATUS
- SHOW TABLES
- SHOW TABLE STATUS
- SHOW TRIGGERS
- SHOW VARIABLES
- SHOW WARNINGS/ERRORS
- UPDATE
- USE db_name
- 系统视图
- GUC参数说明
- 重设参数
- 存储过程
- 标识符说明
- SQL参考
- MySQL语法兼容性评估工具
- Dolphin Extension
- 物化视图
- 分区管理
- 应用程序开发教程
- 性能优化指南
- 参考指南
- 系统表及系统视图
- 系统表和系统视图概述
- 查看系统表
- 系统表
- GS_ASP
- GS_AUDITING_POLICY
- GS_AUDITING_POLICY_ACCESS
- GS_AUDITING_POLICY_FILTERS
- GS_AUDITING_POLICY_PRIVILEGES
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_DB_PRIVILEGE
- GS_ENCRYPTED_COLUMNS
- GS_ENCRYPTED_PROC
- GS_GLOBAL_CHAIN
- GS_GLOBAL_CONFIG
- GS_MASKING_POLICY
- GS_MASKING_POLICY_ACTIONS
- GS_MASKING_POLICY_FILTERS
- GS_MATVIEW
- GS_MATVIEW_DEPENDENCY
- GS_MODEL_WAREHOUSE
- GS_OPT_MODEL
- GS_PACKAGE
- GS_POLICY_LABEL
- GS_RECYCLEBIN
- GS_TXN_SNAPSHOT
- GS_UID
- GS_WLM_EC_OPERATOR_INFO
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_SESSION_QUERY_INFO_ALL
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_AUTHID
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EVENT_TRIGGER
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_HASHBUCKET
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_PUBLICATION
- PG_PUBLICATION_REL
- PG_RANGE
- PG_REPLICATION_ORIGIN
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SET
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SUBSCRIPTION
- PG_SUBSCRIPTION_REL
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PGXC_SLICE
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- 系统视图
- GET_GLOBAL_PREPARED_XACTS(废弃)
- GS_ASYNC_SUBMIT_SESSIONS_STATUS
- GS_AUDITING
- GS_AUDITING_ACCESS
- GS_AUDITING_PRIVILEGE
- GS_CLUSTER_RESOURCE_INFO
- GS_COMPRESSION
- GS_DB_PRIVILEGES
- GS_FILE_STAT
- GS_GSC_MEMORY_DETAIL
- GS_INSTANCE_TIME
- GS_LABELS
- GS_LSC_MEMORY_DETAIL
- GS_MASKING
- GS_MATVIEWS
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY
- GS_SESSION_MEMORY_CONTEXT
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_MEMORY_STATISTICS
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_SHARED_MEMORY_DETAIL
- GS_SQL_COUNT
- GS_STAT_SESSION_CU
- GS_THREAD_MEMORY_CONTEXT
- GS_TOTAL_MEMORY_DETAIL
- GS_WLM_CGROUP_INFO
- GS_WLM_EC_OPERATOR_STATISTICS
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_INFO_ALL
- GS_WLM_SESSION_STATISTICS
- GS_WLM_USER_INFO
- IOS_STATUS
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_COMM_DELAY
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_STATUS
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_ATTACHED_PIDS
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_INDEXES
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_PUBLICATION_TABLES
- PG_REPLICATION_ORIGIN_STATUS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SESSION_IOSTAT
- PG_SESSION_WLMSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_STAT_ACTIVITY
- PG_STAT_ACTIVITY_NG
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_REPLICATION
- PG_STAT_SUBSCRIPTION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_STATS
- PG_TABLES
- PG_TDE_INFO
- PG_THREAD_WAIT_STATUS
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_USER_RESOURCE_INFO
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_USER
- PG_USER_MAPPINGS
- PG_VARIABLE_INFO
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_PREPARED_XACTS
- PLAN_TABLE
- PATCH_INFORMATION_TABLE
- 系统函数
- 逻辑操作符
- 比较操作符
- 字符处理函数和操作符
- 二进制字符串函数和操作符
- 位串函数和操作符
- 模式匹配操作符
- 数字操作函数和操作符
- 时间和日期处理函数和操作符
- 类型转换函数
- 几何函数和操作符
- 网络地址函数和操作符
- 文本检索函数和操作符
- JSON/JSONB函数和操作符
- HLL函数和操作符
- SEQUENCE函数
- 数组函数和操作符
- 范围函数和操作符
- 聚集函数
- 窗口函数(分析函数)
- 安全函数
- 账本数据库的函数
- 密态等值的函数
- 返回集合的函数
- 条件表达式函数
- 系统信息函数
- 系统管理函数
- 统计信息函数
- 触发器函数
- 事件触发器函数
- HashFunc函数
- 提示信息函数
- 全局临时表函数
- 故障注入系统函数
- AI特性函数
- 动态数据脱敏函数
- 其他系统函数
- 内部函数
- Global SysCache特性函数
- 数据损坏检测修复函数
- XML类型函数
- 废弃函数
- 支持的数据类型
- SQL语法
- ABORT
- ALTER AGGREGATE
- ALTER AUDIT POLICY
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER EVENT
- ALTER EVENT TRIGGER
- ALTER EXTENSION
- ALTER FOREIGN DATA WRAPPER
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GLOBAL CONFIGURATION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MASKING POLICY
- ALTER MATERIALIZED VIEW
- ALTER OPERATOR
- ALTER PACKAGE
- ALTER PROCEDURE
- ALTER PUBLICATION
- ALTER RESOURCE LABEL
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SUBSCRIPTION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLE SUBPARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- CONNECT BY
- COPY
- CREATE AGGREGATE
- CREATE AUDIT POLICY
- CREATE CAST
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE EVENT
- CREATE EVENT TRIGGER
- CREATE EXTENSION
- CREATE FOREIGN DATA WRAPPER
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INCREMENTAL MATERIALIZED VIEW
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MASKING POLICY
- CREATE MATERIALIZED VIEW
- CREATE MODEL
- CREATE OPERATOR
- CREATE PACKAGE
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE RESOURCE LABEL
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE ROW LEVEL SECURITY POLICY
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SUBSCRIPTION
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLESPACE
- CREATE TABLE SUBPARTITION
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CREATE WEAK PASSWORD DICTIONARY
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DELIMITER
- DO
- DROP AGGREGATE
- DROP AUDIT POLICY
- DROP CAST
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP EVENT
- DROP EVENT TRIGGER
- DROP EXTENSION
- DROP FOREIGN DATA WRAPPER
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GLOBAL CONFIGURATION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MASKING POLICY
- DROP MATERIALIZED VIEW
- DROP MODEL
- DROP OPERATOR
- DROP OWNED
- DROP PACKAGE
- DROP PROCEDURE
- DROP PUBLICATION
- DROP RESOURCE LABEL
- DROP RESOURCE POOL
- DROP ROLE
- DROP ROW LEVEL SECURITY POLICY
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SUBSCRIPTION
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- DROP WEAK PASSWORD DICTIONARY
- EXECUTE
- EXECUTE DIRECT
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MERGE INTO
- MOVE
- PREDICT BY
- PREPARE
- PREPARE TRANSACTION
- PURGE
- REASSIGN OWNED
- REFRESH INCREMENTAL MATERIALIZED VIEW
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHOW EVENTS
- SHRINK
- SHUTDOWN
- SNAPSHOT
- START TRANSACTION
- TIMECAPSULE TABLE
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- SQL参考
- GUC参数说明
- Schema
- Information Schema
- DBE_PERF
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- LOCAL_ACTIVE_SESSION
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- GLOBAL_SINGLE_FLUSH_DW_STATUS
- GLOBAL_CANDIDATE_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- RTO
- DBE_PLDEBUGGER Schema
- DBE_PLDEBUGGER.turn_on
- DBE_PLDEBUGGER.turn_off
- DBE_PLDEBUGGER.local_debug_server_info
- DBE_PLDEBUGGER.attach
- DBE_PLDEBUGGER.info_locals
- DBE_PLDEBUGGER.next
- DBE_PLDEBUGGER.continue
- DBE_PLDEBUGGER.abort
- DBE_PLDEBUGGER.print_var
- DBE_PLDEBUGGER.info_code
- DBE_PLDEBUGGER.step
- DBE_PLDEBUGGER.add_breakpoint
- DBE_PLDEBUGGER.delete_breakpoint
- DBE_PLDEBUGGER.info_breakpoints
- DBE_PLDEBUGGER.backtrace
- DBE_PLDEBUGGER.disable_breakpoint
- DBE_PLDEBUGGER.enable_breakpoint
- DBE_PLDEBUGGER.finish
- DBE_PLDEBUGGER.set_var
- DB4AI Schema
- DBE_PLDEVELOPER
- DBE_SQL_UTIL Schema
- 工具参考
- 工具一览表
- 客户端工具
- 服务端工具
- 系统内部使用的工具
- dsscmd
- dssserver
- mogdb
- gs_backup
- gs_basebackup
- gs_ctl
- gs_initdb
- gs_install
- gs_postuninstall
- gs_preinstall
- gs_sshexkey
- gs_tar
- gs_uninstall
- gs_upgradectl
- gs_expansion
- gs_dropnode
- gs_probackup
- gstrace
- kdb5_util
- kadmin.local
- kinit
- klist
- krb5kdc
- kdestroy
- pg_config
- pg_controldata
- pg_recvlogical
- pg_resetxlog
- pg_archivecleanup
- pssh
- pscp
- transfer.py
- FAQ
- MogDB可运行脚本功能说明
- gs_collector工具支持收集的系统表和视图列表
- 数据库报错信息
- SQL标准错误码说明
- 第三方库错误码说明
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07500
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53699
- 错误日志信息参考
- 系统表及系统视图
- 故障诊断指南
- 源码解析
- 常见问题解答 (FAQs)
- 术语表
- 通信矩阵
- Mogeaver
UNION,CASE和相关构造
SQL UNION构造必须把那些可能不太相似的类型匹配起来成为一个结果集。解析算法分别应用于联合查询的每个输出字段。INTERSECT和EXCEPT构造对不相同的类型使用和UNION相同的算法进行解析。CASE、ARRAY、VALUES、GREATEST和LEAST构造也使用同样的算法匹配它的部件表达式并且选择一个结果数据类型。
UNION,CASE和相关构造解析
-
如果所有输入都是相同的类型,并且不是unknown类型,那么解析成这种类型。
-
如果所有输入都是unknown类型则解析成text类型(字符串类型范畴的首选类型)。否则,忽略unknown输入。
-
如果输入不属于同一个类型范畴,失败。(unknown类型除外)
-
如果输入类型是同一个类型范畴,则选择该类型范畴的首选类型。(例外:union操作会选择第一个分支的类型作为所选类型。)
 说明:
系统表pg_type中typcategory表示数据类型范畴, typispreferred表示是否是typcategory分类中的首选类型。
说明:
系统表pg_type中typcategory表示数据类型范畴, typispreferred表示是否是typcategory分类中的首选类型。 -
把所有输入转换为所选的类型(对于字符串保持原有长度)。如果从给定的输入到所选的类型没有隐式转换则失败。
-
若输入中含json、txid_snapshot、sys_refcursor或几何类型,则不能进行union。
对于case和coalesce,在TD兼容模式下的处理
- 如果所有输入都是相同的类型,并且不是unknown类型,那么解析成这种类型。
- 如果所有输入都是unknown类型则解析成text类型。
- 如果输入字符串(包括unknown,unknown当text来处理)和数字类型,那么解析成字符串类型,如果是其他不同的类型范畴,则报错。
- 如果输入类型是同一个类型范畴,则选择该类型的优先级较高的类型。
- 把所有输入转换为所选的类型。如果从给定的输入到所选的类型没有隐式转换则失败。
对于case,在ORA兼容模式下的处理
decode(expr, search1, result1, search2, result2, …, defresult),也即 case expr when search1 then result1 when search2 then result2 else defresult end; 在ORA兼容模式下的处理,将整个表达式最终的返回值类型定为result1的数据类型,或者与result1同类型范畴的更高精度的数据类型。(例如,numeric与int同属数值类型范畴,但numeric比int精度要高,具有更高优先级)
- 将result1的数据类型置为最终的返回值类型preferType,其所属类型范畴为preferCategory。
- 依次考虑result2、result3直至defresult的数据类型。如果其类型范畴也是preferCategory,即与result1具有相同的类型范畴,则判断其精度(优先级)是否高于preferType,如果高于,则将preferType更新为更高精度的数据类型;如果其类型范畴不是preferCategory,则判断其数据类型是否可以隐式转换为preferType,不可以则报错。
- 将最终preferType记录的数据类型作为整个表达式最终的返回值类型;表达式的结果向此类型进行隐式转换。
注1:
为了兼容一种特殊情况,即表示了超大数字的字符类型向数值类型转换的情况,例如select decode(1, 2, 2, “53465465676465454657567678676”),大数超过了bigint、double等的表示范围。所以,当result1的类型范畴为数值类型时,将返回值的类型直接置为numeric,以兼容此种特殊情况。
注2:
数值类型的优先级排序:numeric>float8>float4>int8>int4>int2>int1
字符类型的优先级排序:text>varchar=nvarchar2>bpchar>char
日期类型的优先级排序:timestamptz>timestamp>smalldatetime>date>abstime>timetz>time
日期跨度类型的优先级排序:interval>tinterval>reltime
注3:
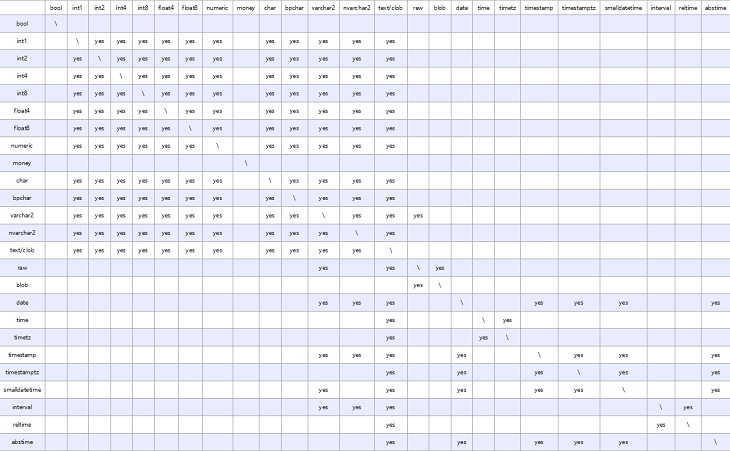
ORA兼容模式,开启 set sql_beta_feature = 'a_style_coerce'; 参数的情况下,所支持的隐式类型转换见下图,\代表不需要转换,yes表示支持,空白表示不支持。
示例
示例1:Union中的待定类型解析。这里,unknown类型文本'b'将被解析成text类型。
MogDB=# SELECT text 'a' AS "text" UNION SELECT 'b';
text
------
a
b
(2 rows)示例2:简单Union中的类型解析。文本1.2的类型为numeric,而且integer类型的1可以隐含地转换为numeric,因此使用这个类型。
MogDB=# SELECT 1.2 AS "numeric" UNION SELECT 1;
numeric
---------
1
1.2
(2 rows)示例3:转置Union中的类型解析。这里,因为类型real不能被隐含转换成integer,但是integer可以隐含转换成real,那么联合的结果类型将是real。
MogDB=# SELECT 1 AS "real" UNION SELECT CAST('2.2' AS REAL);
real
------
1
2.2
(2 rows)示例4:TD模式下,coalesce参数输入int和varchar类型,那么解析成varchar类型。A模式下会报错。
--在A模式下,创建A兼容模式的数据库a_1。
MogDB=# CREATE DATABASE a_1 dbcompatibility = 'A';
--切换数据库为a_1。
MogDB=# \c a_1
--创建表t1。
a_1=# CREATE TABLE t1(a int, b varchar(10));
--查看coalesce参数输入int和varchar类型的查询语句的执行计划。
a_1=# EXPLAIN SELECT coalesce(a, b) FROM t1;
ERROR: COALESCE types integer and character varying cannot be matched
LINE 1: EXPLAIN SELECT coalesce(a, b) FROM t1;
^
CONTEXT: referenced column: coalesce
--删除表。
a_1=# DROP TABLE t1;
--切换数据库为mogdb。
a_1=# \c mogdb
--在TD模式下,创建TD兼容模式的数据库td_1。
MogDB=# CREATE DATABASE td_1 dbcompatibility = 'C';
--切换数据库为td_1。
MogDB=# \c td_1
--创建表t2。
td_1=# CREATE TABLE t2(a int, b varchar(10));
--查看coalesce参数输入int和varchar类型的查询语句的执行计划。
td_1=# EXPLAIN VERBOSE select coalesce(a, b) from t2;
QUERY PLAN
---------------------------------------------------------------------------------------
Seq Scan on public.t2 (cost=0.00..31.27 rows=1702 width=18)
Output: COALESCE((a)::character varying, b)
(2 rows)
--删除表。
td_1=# DROP TABLE t2;
--切换数据库为mogdb。
td_1=# \c mogdb
--删除A和TD模式的数据库。
MogDB=# DROP DATABASE a_1;
MogDB=# DROP DATABASE td_1;示例5:ORA模式下,将整个表达式最终的返回值类型定为result1的数据类型,或者与result1同类型范畴的更高精度的数据类型。
--在ORA模式下,创建ORA兼容模式的数据库ora_1。
MogDB=# CREATE DATABASE ora_1 dbcompatibility = 'A';
--切换数据库为ora_1。
MogDB=# \c ora_1
--开启Decode兼容性参数。
set sql_beta_feature='a_style_coerce';
--创建表t1。
ora_1=# CREATE TABLE t1(c_int int, c_float8 float8, c_char char(10), c_text text, c_date date);
--插入数据。
ora_1=# INSERT INTO t1 VALUES(1, 2, '3', '4', date '12-10-2010');
--result1类型为char,defresult类型为text,text精度更高,返回值的类型由char更新为text。
ora_1=# SELECT decode(1, 2, c_char, c_text) AS result, pg_typeof(result) FROM t1;
result | pg_typeof
--------+-----------
4 | text
(1 row)
--result1类型为int,属于数值类型范畴,返回值的类型置为numeric。
ora_1=# SELECT decode(1, 2, c_int, c_float8) AS result, pg_typeof(result) FROM t1;
result | pg_typeof
--------+-----------
2 | numeric
(1 row)
--不存在defresult数据类型向result1数据类型之间的隐式转换,报错处理。
ora_1=# SELECT decode(1, 2, c_int, c_date) FROM t1;
ERROR: CASE types integer and timestamp without time zone cannot be matched
LINE 1: SELECT decode(1, 2, c_int, c_date) FROM t1;
^
CONTEXT: referenced column: c_date
--关闭Decode兼容性参数。
set sql_beta_feature='none';
--删除表。
ora_1=# DROP TABLE t1;
DROP TABLE
--切换数据库为postgres。
ora_1=# \c postgres
--删除ORA模式的数据库。
MogDB=# DROP DATABASE ora_1;
DROP DATABASE