- 关于MogDB
- 快速入门
- MogDB实训平台
- 容器化安装
- 单节点安装
- 访问数据库
- 使用命令行访问MogDB
- 使用图形工具访问MogDB
- 使用中间件访问MogDB
- 使用编程语言访问MogDB
- 使用样本数据集Mogila
- 特性描述
- 概览
- 高性能
- 高可用
- 维护性
- 数据库安全
- 企业级特性
- 应用开发接口
- AI能力
- AI4DB:数据库自治运维
- DB4AI:数据库驱动AI
- AI in DB:数据库内AI功能
- ABO优化器
- 中间件
- 安装指南
- 管理指南
- 本地化
- 日常运维
- 主备管理
- MOT内存表管理
- 列存表管理
- 备份与恢复
- 两地三中心跨Region容灾
- 数据导出导入
- 升级指南
- AI特性指南
- AI特性概述
- AI4DB:数据库自治运维
- DBMind模式说明
- DBMind的支持组件
- DBMind的AI子功能
- DB4AI:数据库驱动AI
- AI in DB:数据库内AI功能
- ABO 优化器
- 安全指南
- 开发者指南
- 应用程序开发教程
- 开发规范
- 基于JDBC开发
- 概述
- JDBC包、驱动类和环境类
- 开发流程
- 加载驱动
- 连接数据库
- 连接数据库(以SSL方式)
- 连接数据库(UDS方式)
- 执行SQL语句
- 处理结果集
- 关闭连接
- 日志管理
- 示例:常用操作
- 示例:重新执行应用SQL
- 示例:通过本地文件导入导出数据
- 示例:从MY向MogDB进行数据迁移
- 示例:逻辑复制代码示例
- 示例:不同场景下连接数据库参数配置
- JDBC接口参考
- java.sql.Connection
- java.sql.CallableStatement
- java.sql.DatabaseMetaData
- java.sql.Driver
- java.sql.PreparedStatement
- java.sql.ResultSet
- java.sql.ResultSetMetaData
- java.sql.Statement
- javax.sql.ConnectionPoolDataSource
- javax.sql.DataSource
- javax.sql.PooledConnection
- javax.naming.Context
- javax.naming.spi.InitialContextFactory
- CopyManager
- JDBC常用参数参考
- 基于ODBC开发
- 基于libpq开发
- libpq使用依赖的头文件
- 开发流程
- 示例
- 链接参数
- libpq接口参考
- 数据库连接控制函数
- 数据库执行语句函数
- 异步命令处理
- 取消正在处理的查询
- 基于Psycopg开发
- 调试
- 存储过程
- 用户自定义函数
- PL/pgSQL-SQL过程语言
- 定时任务
- 自治事务
- 逻辑复制
- Extension
- PostGIS Extension
- Foreign Data Wrapper
- orafce
- pg_bulkload
- pg_prewarm
- pg_repack
- pg_trgm
- wal2json
- whale
- 物化视图
- 分区管理
- 应用程序开发教程
- 性能优化指南
- 参考指南
- 系统表及系统视图
- 系统表和系统视图概述
- 系统表
- GS_ASP
- GS_AUDITING_POLICY
- GS_AUDITING_POLICY_ACCESS
- GS_AUDITING_POLICY_FILTERS
- GS_AUDITING_POLICY_PRIVILEGES
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_DB_PRIVILEGE
- GS_ENCRYPTED_COLUMNS
- GS_ENCRYPTED_PROC
- GS_GLOBAL_CHAIN
- GS_GLOBAL_CONFIG
- GS_MASKING_POLICY
- GS_MASKING_POLICY_ACTIONS
- GS_MASKING_POLICY_FILTERS
- GS_MATVIEW
- GS_MATVIEW_DEPENDENCY
- GS_MODEL_WAREHOUSE
- GS_OPT_MODEL
- GS_PACKAGE
- GS_POLICY_LABEL
- GS_RECYCLEBIN
- GS_TXN_SNAPSHOT
- GS_UID
- GS_WLM_EC_OPERATOR_INFO
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_SESSION_QUERY_INFO_ALL
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_AUTHID
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_HASHBUCKET
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_PUBLICATION
- PG_PUBLICATION_REL
- PG_RANGE
- PG_REPLICATION_ORIGIN
- PG_RESOURCE_POOL
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SET
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SUBSCRIPTION
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PGXC_SLICE
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- 系统视图
- DV_SESSION_LONGOPS
- DV_SESSIONS
- GET_GLOBAL_PREPARED_XACTS(废弃)
- GS_AUDITING
- GS_AUDITING_ACCESS
- GS_AUDITING_PRIVILEGE
- GS_ASYNC_SUBMIT_SESSIONS_STATUS
- GS_CLUSTER_RESOURCE_INFO
- GS_COMPRESSION
- GS_DB_PRIVILEGES
- GS_FILE_STAT
- GS_GSC_MEMORY_DETAIL
- GS_INSTANCE_TIME
- GS_LABELS
- GS_LSC_MEMORY_DETAIL
- GS_MASKING
- GS_MATVIEWS
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY
- GS_SESSION_MEMORY_CONTEXT
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_MEMORY_STATISTICS
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_SQL_COUNT
- GS_STAT_SESSION_CU
- GS_THREAD_MEMORY_CONTEXT
- GS_TOTAL_MEMORY_DETAIL
- GS_WLM_CGROUP_INFO
- GS_WLM_EC_OPERATOR_STATISTICS
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_INFO_ALL
- GS_WLM_SESSION_STATISTICS
- GS_WLM_USER_INFO
- GS_WRITE_TERM_LOG
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_COMM_DELAY
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_STATUS
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_ATTACHED_PIDS
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_INDEXES
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_PUBLICATION_TABLES
- PG_REPLICATION_ORIGIN_STATUS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SESSION_IOSTAT
- PG_SESSION_WLMSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_STAT_ACTIVITY
- PG_STAT_ACTIVITY_NG
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_REPLICATION
- PG_STAT_SUBSCRIPTION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_STATS
- PG_TABLES
- PG_TDE_INFO
- PG_THREAD_WAIT_STATUS
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_USER_RESOURCE_INFO
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_USER
- PG_USER_MAPPINGS
- PG_VARIABLE_INFO
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_PREPARED_XACTS
- PLAN_TABLE
- 系统函数
- 逻辑操作符
- 比较操作符
- 字符处理函数和操作符
- 二进制字符串函数和操作符
- 位串函数和操作符
- 模式匹配操作符
- 数字操作函数和操作符
- 时间和日期处理函数和操作符
- 类型转换函数
- 几何函数和操作符
- 网络地址函数和操作符
- 文本检索函数和操作符
- JSON/JSONB函数和操作符
- HLL函数和操作符
- SEQUENCE函数
- 数组函数和操作符
- 范围函数和操作符
- 聚集函数
- 窗口函数(分析函数)
- 安全函数
- 账本数据库的函数
- 密态等值的函数
- 返回集合的函数
- 条件表达式函数
- 系统信息函数
- 系统管理函数
- 统计信息函数
- 触发器函数
- HashFunc函数
- 提示信息函数
- 全局临时表函数
- 故障注入系统函数
- AI特性函数
- 动态数据脱敏函数
- 其他系统函数
- 内部函数
- Global SysCache特性函数
- 数据损坏检测修复函数
- 废弃函数
- 支持的数据类型
- SQL语法
- ABORT
- ALTER AGGREGATE
- ALTER AUDIT POLICY
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER EXTENSION
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GLOBAL CONFIGURATION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MASKING POLICY
- ALTER MATERIALIZED VIEW
- ALTER PACKAGE
- ALTER PROCEDURE
- ALTER PUBLICATION
- ALTER RESOURCE LABEL
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SUBSCRIPTION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLE SUBPARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- CONNECT BY
- COPY
- CREATE AGGREGATE
- CREATE AUDIT POLICY
- CREATE CAST
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE EXTENSION
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INCREMENTAL MATERIALIZED VIEW
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MASKING POLICY
- CREATE MATERIALIZED VIEW
- CREATE MODEL
- CREATE OPERATOR
- CREATE PACKAGE
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE RESOURCE LABEL
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE ROW LEVEL SECURITY POLICY
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SUBSCRIPTION
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLE SUBPARTITION
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CREATE WEAK PASSWORD DICTIONARY
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DO
- DROP AGGREGATE
- DROP AUDIT POLICY
- DROP CAST
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP EXTENSION
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GLOBAL CONFIGURATION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MASKING POLICY
- DROP MATERIALIZED VIEW
- DROP MODEL
- DROP OPERATOR
- DROP OWNED
- DROP PACKAGE
- DROP PROCEDURE
- DROP PUBLICATION
- DROP RESOURCE LABEL
- DROP RESOURCE POOL
- DROP ROLE
- DROP ROW LEVEL SECURITY POLICY
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SUBSCRIPTION
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- DROP WEAK PASSWORD DICTIONARY
- EXECUTE
- EXECUTE DIRECT
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MERGE INTO
- MOVE
- PREDICT BY
- PREPARE
- PREPARE TRANSACTION
- PURGE
- REASSIGN OWNED
- REFRESH INCREMENTAL MATERIALIZED VIEW
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHUTDOWN
- SNAPSHOT
- START TRANSACTION
- TIMECAPSULE TABLE
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- SHRINK
- SQL参考
- GUC参数说明
- Schema
- 概述
- Information Schema
- DBE_PERF
- 概述
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- LOCAL_ACTIVE_SESSION
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- GLOBAL_SINGLE_FLUSH_DW_STATUS
- GLOBAL_CANDIDATE_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- RTO
- DBE_PLDEBUGGER Schema
- DBE_PLDEBUGGER Schema概述
- DBE_PLDEBUGGER.turn_on
- DBE_PLDEBUGGER.turn_off
- DBE_PLDEBUGGER.local_debug_server_info
- DBE_PLDEBUGGER.attach
- DBE_PLDEBUGGER.info_locals
- DBE_PLDEBUGGER.next
- DBE_PLDEBUGGER.continue
- DBE_PLDEBUGGER.abort
- DBE_PLDEBUGGER.print_var
- DBE_PLDEBUGGER.info_code
- DBE_PLDEBUGGER.step
- DBE_PLDEBUGGER.add_breakpoint
- DBE_PLDEBUGGER.delete_breakpoint
- DBE_PLDEBUGGER.info_breakpoints
- DBE_PLDEBUGGER.backtrace
- DBE_PLDEBUGGER.disable_breakpoint
- DBE_PLDEBUGGER.enable_breakpoint
- DBE_PLDEBUGGER.finish
- DBE_PLDEBUGGER.set_var
- DB4AI Schema
- DBE_PLDEVELOPER
- 工具参考
- 数据库报错信息
- SQL标准错误码说明
- 第三方库错误码说明
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07480
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53799
- 错误日志信息参考
- 系统表及系统视图
- 故障诊断指南
- 常见故障定位手段
- 常见故障定位案例
- core问题定位
- 权限/会话/数据类型问题定位
- 服务/高可用/并发问题定位
- 表/分区表问题定位
- 文件系统/磁盘/内存问题定位
- SQL问题定位
- 索引问题定位
- CM两节点故障问题定位
- 源码解析
- 常见问题解答 (FAQs)
- 术语表
- 通信矩阵
- Mogeaver
使用Plan Hint进行调优
Plan Hint调优概述
Plan Hint为用户提供了直接影响执行计划生成的手段,用户可以通过指定join顺序,join、scan方法,指定结果行数,等多个手段来进行执行计划的调优,以提升查询的性能。
MogDB还提供了SQL PATCH功能,在不修改业务语句的前提下通过创建SQL PATCH的方式使得Hint生效。
功能描述
Plan Hint支持在SELECT关键字后通过如下形式指定:
/*+ <plan hint>*/可以同时指定多个hint,之间使用空格分隔。hint只能hint当前层的计划,对于子查询计划的hint,需要在子查询的select关键字后指定hint。
例如:
select /*+ <plan_hint1> <plan_hint2> */ * from t1, (select /*+ <plan_hint3> */ from t2) where 1=1;其中<plan_hint1>,<plan_hint2>为外层查询的hint,<plan_hint3>为内层子查询的hint。
须知: 如果在视图定义(CREATE VIEW)时指定hint,则在该视图每次被应用时会使用该hint。 当使用random plan功能(参数plan_mode_seed不为0)时,查询指定的plan hint不会被使用。
支持范围
当前版本Plan Hint支持的范围如下,后续版本会进行增强。
- 指定Join顺序的Hint - leading hint
- 指定Join方式的Hint,仅支持除semi/anti join,unique plan之外的常用hint。
- 指定结果集行数的Hint
- 指定Scan方式的Hint,仅支持常用的tablescan,indexscan和indexonlyscan的hint。
- 指定子链接块名的Hint
注意事项
不支持Agg、Sort、Setop和Subplan的hint。
示例
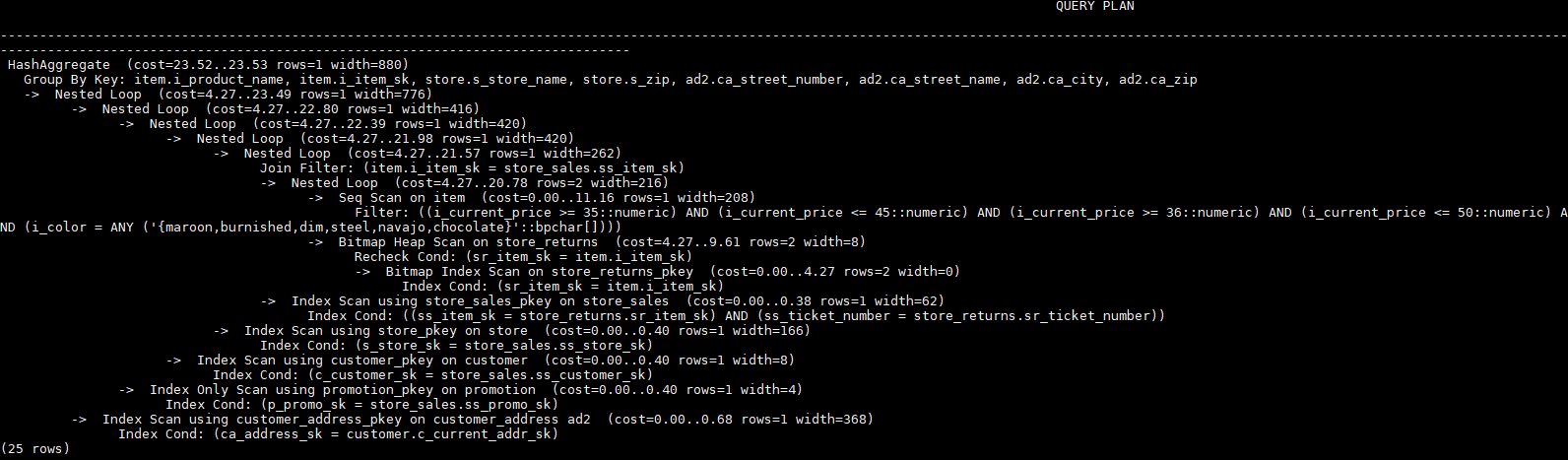
本章节使用同一个语句进行示例,便于Plan Hint支持的各方法作对比,示例语句及不带hint的原计划如下所示:
create table store
(
s_store_sk integer not null,
s_store_id char(16) not null,
s_rec_start_date date ,
s_rec_end_date date ,
s_closed_date_sk integer ,
s_store_name varchar(50) ,
s_number_employees integer ,
s_floor_space integer ,
s_hours char(20) ,
s_manager varchar(40) ,
s_market_id integer ,
s_geography_class varchar(100) ,
s_market_desc varchar(100) ,
s_market_manager varchar(40) ,
s_division_id integer ,
s_division_name varchar(50) ,
s_company_id integer ,
s_company_name varchar(50) ,
s_street_number varchar(10) ,
s_street_name varchar(60) ,
s_street_type char(15) ,
s_suite_number char(10) ,
s_city varchar(60) ,
s_county varchar(30) ,
s_state char(2) ,
s_zip char(10) ,
s_country varchar(20) ,
s_gmt_offset decimal(5,2) ,
s_tax_precentage decimal(5,2) ,
primary key (s_store_sk)
);
create table store_sales
(
ss_sold_date_sk integer ,
ss_sold_time_sk integer ,
ss_item_sk integer not null,
ss_customer_sk integer ,
ss_cdemo_sk integer ,
ss_hdemo_sk integer ,
ss_addr_sk integer ,
ss_store_sk integer ,
ss_promo_sk integer ,
ss_ticket_number integer not null,
ss_quantity integer ,
ss_wholesale_cost decimal(7,2) ,
ss_list_price decimal(7,2) ,
ss_sales_price decimal(7,2) ,
ss_ext_discount_amt decimal(7,2) ,
ss_ext_sales_price decimal(7,2) ,
ss_ext_wholesale_cost decimal(7,2) ,
ss_ext_list_price decimal(7,2) ,
ss_ext_tax decimal(7,2) ,
ss_coupon_amt decimal(7,2) ,
ss_net_paid decimal(7,2) ,
ss_net_paid_inc_tax decimal(7,2) ,
ss_net_profit decimal(7,2) ,
primary key (ss_item_sk, ss_ticket_number)
);
create table store_returns
(
sr_returned_date_sk integer ,
sr_return_time_sk integer ,
sr_item_sk integer not null,
sr_customer_sk integer ,
sr_cdemo_sk integer ,
sr_hdemo_sk integer ,
sr_addr_sk integer ,
sr_store_sk integer ,
sr_reason_sk integer ,
sr_ticket_number integer not null,
sr_return_quantity integer ,
sr_return_amt decimal(7,2) ,
sr_return_tax decimal(7,2) ,
sr_return_amt_inc_tax decimal(7,2) ,
sr_fee decimal(7,2) ,
sr_return_ship_cost decimal(7,2) ,
sr_refunded_cash decimal(7,2) ,
sr_reversed_charge decimal(7,2) ,
sr_store_credit decimal(7,2) ,
sr_net_loss decimal(7,2) ,
primary key (sr_item_sk, sr_ticket_number)
);
create table customer
(
c_customer_sk integer not null,
c_customer_id char(16) not null,
c_current_cdemo_sk integer ,
c_current_hdemo_sk integer ,
c_current_addr_sk integer ,
c_first_shipto_date_sk integer ,
c_first_sales_date_sk integer ,
c_salutation char(10) ,
c_first_name char(20) ,
c_last_name char(30) ,
c_preferred_cust_flag char(1) ,
c_birth_day integer ,
c_birth_month integer ,
c_birth_year integer ,
c_birth_country varchar(20) ,
c_login char(13) ,
c_email_address char(50) ,
c_last_review_date char(10) ,
primary key (c_customer_sk)
);
create table promotion
(
p_promo_sk integer not null,
p_promo_id char(16) not null,
p_start_date_sk integer ,
p_end_date_sk integer ,
p_item_sk integer ,
p_cost decimal(15,2) ,
p_response_target integer ,
p_promo_name char(50) ,
p_channel_dmail char(1) ,
p_channel_email char(1) ,
p_channel_catalog char(1) ,
p_channel_tv char(1) ,
p_channel_radio char(1) ,
p_channel_press char(1) ,
p_channel_event char(1) ,
p_channel_demo char(1) ,
p_channel_details varchar(100) ,
p_purpose char(15) ,
p_discount_active char(1) ,
primary key (p_promo_sk)
);
create table customer_address
(
ca_address_sk integer not null,
ca_address_id char(16) not null,
ca_street_number char(10) ,
ca_street_name varchar(60) ,
ca_street_type char(15) ,
ca_suite_number char(10) ,
ca_city varchar(60) ,
ca_county varchar(30) ,
ca_state char(2) ,
ca_zip char(10) ,
ca_country varchar(20) ,
ca_gmt_offset decimal(5,2) ,
ca_location_type char(20) ,
primary key (ca_address_sk)
);
create table item
(
i_item_sk integer not null,
i_item_id char(16) not null,
i_rec_start_date date ,
i_rec_end_date date ,
i_item_desc varchar(200) ,
i_current_price decimal(7,2) ,
i_wholesale_cost decimal(7,2) ,
i_brand_id integer ,
i_brand char(50) ,
i_class_id integer ,
i_class char(50) ,
i_category_id integer ,
i_category char(50) ,
i_manufact_id integer ,
i_manufact char(50) ,
i_size char(20) ,
i_formulation char(20) ,
i_color char(20) ,
i_units char(10) ,
i_container char(10) ,
i_manager_id integer ,
i_product_name char(50) ,
primary key (i_item_sk)
);
explain
select i_product_name product_name
,i_item_sk item_sk
,s_store_name store_name
,s_zip store_zip
,ad2.ca_street_number c_street_number
,ad2.ca_street_name c_street_name
,ad2.ca_city c_city
,ad2.ca_zip c_zip
,count(*) cnt
,sum(ss_wholesale_cost) s1
,sum(ss_list_price) s2
,sum(ss_coupon_amt) s3
FROM store_sales
,store_returns
,store
,customer
,promotion
,customer_address ad2
,item
WHERE ss_store_sk = s_store_sk AND
ss_customer_sk = c_customer_sk AND
ss_item_sk = i_item_sk and
ss_item_sk = sr_item_sk and
ss_ticket_number = sr_ticket_number and
c_current_addr_sk = ad2.ca_address_sk and
ss_promo_sk = p_promo_sk and
i_color in ('maroon','burnished','dim','steel','navajo','chocolate') and
i_current_price between 35 and 35 + 10 and
i_current_price between 35 + 1 and 35 + 15
group by i_product_name
,i_item_sk
,s_store_name
,s_zip
,ad2.ca_street_number
,ad2.ca_street_name
,ad2.ca_city
,ad2.ca_zip
;
Join顺序的Hint
功能描述
指明join的顺序,包括内外表顺序。
语法格式
-
仅指定join顺序,不指定内外表顺序。
leading(join_table_list) -
同时指定join顺序和内外表顺序,内外表顺序仅在最外层生效。
leading((join_table_list))
参数说明
join_table_list为表示表join顺序的hint字符串,可以包含当前层的任意个表(别名),或对于子查询提升的场景,也可以包含子查询的hint别名,同时任意表可以使用括号指定优先级,表之间使用空格分隔。
join table list中指定的表需要满足以下要求,否则会报语义错误。
- list中的表必须在当前层或提升的子查询中存在。
- list中的表在当前层或提升的子查询中必须是唯一的。如果不唯一,需要使用不同的别名进行区分。
- 同一个表只能在list里出现一次。
- 如果表存在别名,则list中的表需要使用别名。
例如:
leading(t1 t2 t3 t4 t5)表示: t1,t2,t3,t4,t5先join,五表join顺序及内外表不限。
leading((t1 t2 t3 t4 t5))表示: t1和t2先join,t2做内表;再和t3 join,t3做内表;再和t4 join,t4做内表;再和t5 join,t5做内表。
leading(t1 (t2 t3 t4) t5)表示: t2,t3,t4先join,内外表不限;再和t1,t5 join,内外表不限。
leading((t1 (t2 t3 t4) t5))表示: t2,t3,t4先join,内外表不限;在最外层,t1再和t2,t3,t4的join表join,t1为外表,再和t5 join,t5为内表。
leading((t1 (t2 t3) t4 t5)) leading((t3 t2))表示: t2,t3先join,t2做内表;然后再和t1 join,t2,t3的join表做内表;然后再依次跟t4,t5做join,t4,t5做内表。
示例
对示例中原语句使用如下hint:
explain
select /*+ leading((((((store_sales store) promotion) item) customer) ad2) store_returns) leading((store store_sales))*/ i_product_name product_name ...该hint表示: 表之间的join关系是: store_sales和store先join,store_sales做内表,然后依次跟promotion, item, customer, ad2, store_returns做join。生成计划如下所示:
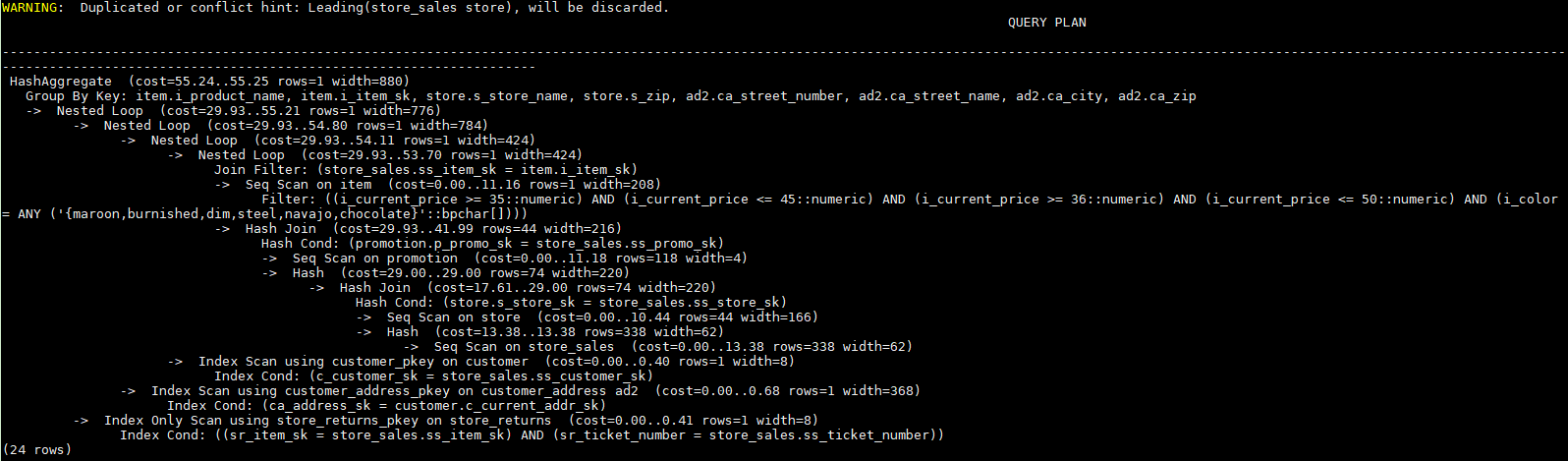
Join方式的Hint
功能描述
指明Join使用的方法,可以为Nested Loop,Hash Join和Merge Join。
语法格式
[no] nestloop|hashjoin|mergejoin(table_list)参数说明
例如:
no nestloop(t1 t2 t3)表示: 生成t1,t2,t3三表连接计划时,不使用nestloop。三表连接计划可能是t2 t3先join,再跟t1 join,或t1 t2先join,再跟t3 join。此hint只hint最后一次join的join方式,对于两表连接的方法不hint。如果需要,可以单独指定,例如: 任意表均不允许nestloop连接,且希望t2 t3先join,则增加hint: no nestloop(t2 t3)。
示例
对示例中原语句使用如下hint:
explain
select /*+ nestloop(store_sales store_returns item) */ i_product_name product_name ...该hint表示: 生成store_sales,store_returns和item三表的结果集时,最后的两表关联使用nestloop。生成计划如下所示:
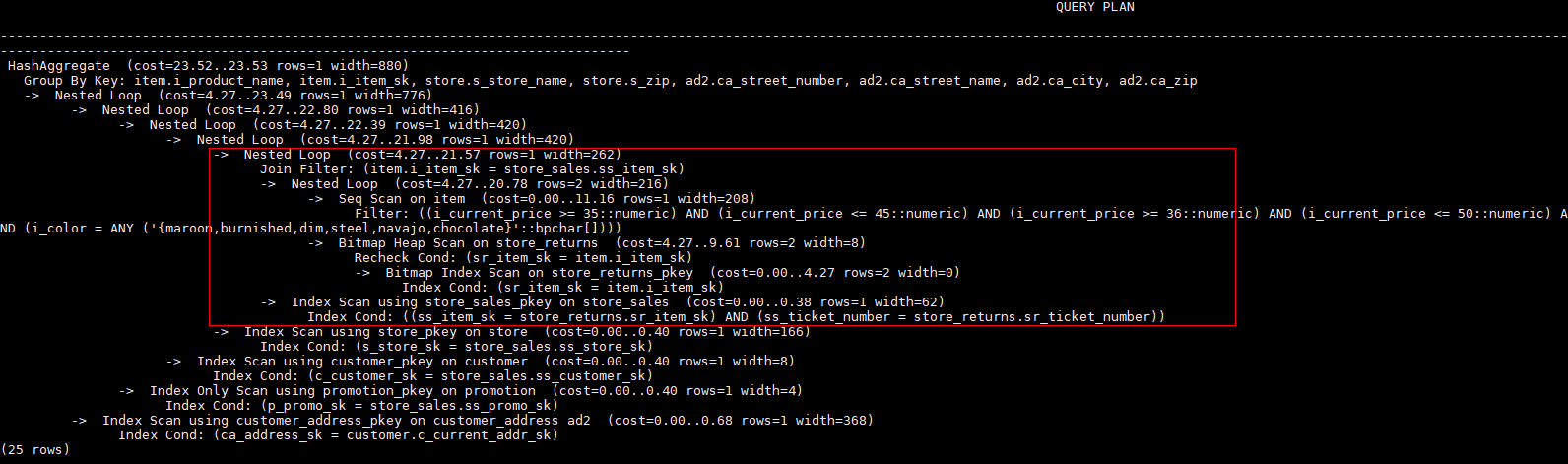
行数的Hint
功能描述
指明中间结果集的大小,支持绝对值和相对值的hint。
语法格式
rows(table_list #|+|-|* const)参数说明
- #,+,-,*****,进行行数估算hint的四种操作符号。#表示直接使用后面的行数进行hint。+,-,*表示对原来估算的行数进行加、减、乘操作,运算后的行数最小值为1行。table_list为hint对应的单表或多表join结果集,与Join方式的Hint中table_list相同。
- const可以是任意非负数,支持科学计数法。
例如:
rows(t1 #5)表示: 指定t1表的结果集为5行。
rows(t1 t2 t3 *1000)表示: 指定t1, t2, t3 join完的结果集的行数乘以1000。
建议
- 推荐使用两个表的hint。对于两个表的采用*操作符的hint,只要两个表出现在join的两端,都会触发hint。例如: 设置hint为rows(t1 t2 * 3),对于(t1 t3 t4)和(t2 t5 t6)join时,由于t1和t2出现在join的两端,所以其join的结果集也会应用该hint规则乘以3。
- rows hint支持在单表、多表、function table及subquery scan table的结果集上指定hint。
示例
对示例中原语句使用如下hint:
explain
select /*+ rows(store_sales store_returns *50) */ i_product_name product_name ...该hint表示: store_sales,store_returns关联的结果集估算行数在原估算行数基础上乘以50。生成计划如下所示:
Scan方式的Hint
功能描述
指明scan使用的方法,可以是tablescan、indexscan和indexonlyscan。
语法格式
[no] tablescan|indexscan|indexonlyscan(table [index])参数说明
- no表示hint的scan方式不使用。
- table表示hint指定的表,只能指定一个表,如果表存在别名应优先使用别名进行hint。
- index表示使用indexscan或indexonlyscan的hint时,指定的索引名称,当前只能指定一个。
说明: 对于indexscan或indexonlyscan,只有hint的索引属于hint的表时,才能使用该hint。 scan hint支持在行列存表、obs表、子查询表上指定。
示例
为了hint使用索引扫描,需要首先在表item的i_item_sk列上创建索引,名称为i。
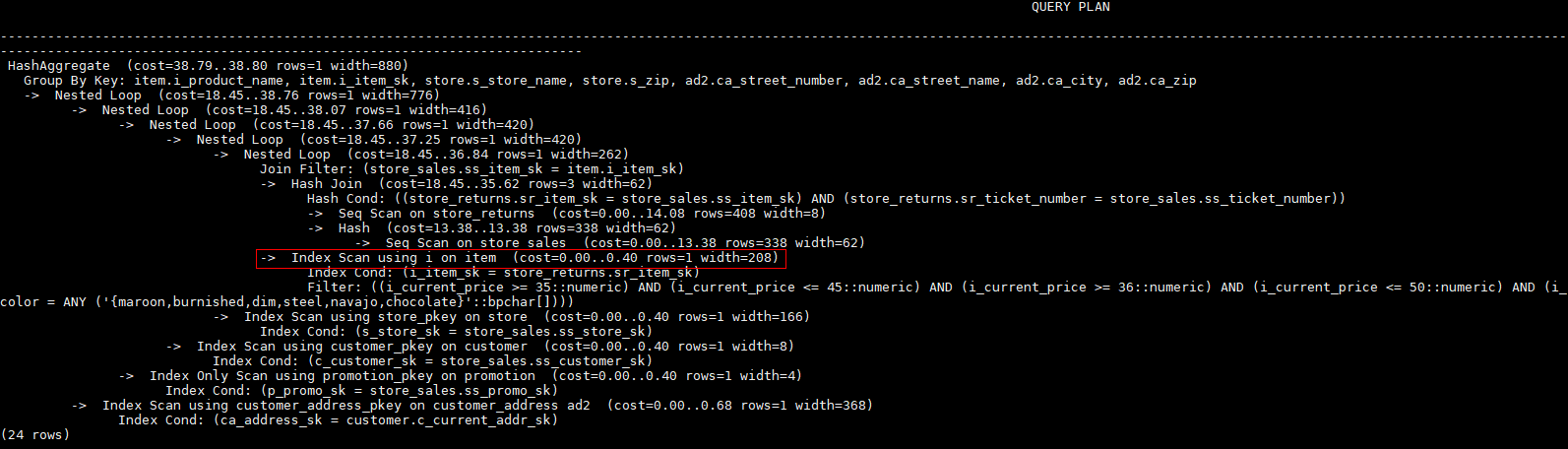
create index i on item(i_item_sk);对示例中原语句使用如下hint:
explain
select /*+ indexscan(item i) */ i_product_name product_name ...该hint表示: item表使用索引i进行扫描。生成计划如下所示:
子链接块名的hint
功能描述
指明子链接块的名称。
语法格式
blockname (table)参数说明
- table表示为该子链接块hint的别名的名称。
- blockname hint仅在对应的子链接块没有提升时才会被上层查询使用。目前支持的子链接提升包括IN子链接提升、EXISTS子链接提升和包含Agg等值相关子链接提升。该hint通常会和前面章节提到的hint联合使用。
- 对于FROM关键字后的子查询,则需要使用子查询的别名进行hint,blockname hint不会被用到。
- 如果子链接中含有多个表,则提升后这些表可与外层表以任意优化顺序连接,hint也不会被用到。
示例
explain select /*+nestloop(store_sales tt) */ * from store_sales where ss_item_sk in (select /*+blockname(tt)*/ i_item_sk from item group by 1);该hint表示: 子链接的别名为tt,提升后与上层的store_sales表关联时使用nestloop。生成计划如下所示:

Hint的错误、冲突及告警
Plan Hint的结果会体现在计划的变化上,可以通过explain来查看变化。
Hint中的错误不会影响语句的执行,只是不能生效,该错误会根据语句类型以不同方式提示用户。对于explain语句,hint的错误会以warning形式显示在界面上,对于非explain语句,会以debug1级别日志显示在日志中,关键字为PLANHINT。
hint的错误分为以下类型:
-
语法错误
语法规则树归约失败,会报错,指出出错的位置。
例如: hint关键字错误,leading hint或join hint指定2个表以下,其它hint未指定表等。一旦发现语法错误,则立即终止hint的解析,所以此时只有错误前面的解析完的hint有效。
例如:
leading((t1 t2)) nestloop(t1) rows(t1 t2 #10)nestloop(t1)存在语法错误,则终止解析,可用hint只有之前解析的leading((t1 t2))。
-
语义错误
- 表不存在,存在多个,或在leading或join中出现多次,均会报语义错误。
- scanhint中的index不存在,会报语义错误。
- 另外,如果子查询提升后,同一层出现多个名称相同的表,且其中某个表需要被hint,hint会存在歧义,无法使用,需要为相同表增加别名规避。
-
hint重复或冲突
如果存在hint重复或冲突,只有第一个hint生效,其它hint均会失效,会给出提示。
-
hint重复是指,hint的方法及表名均相同。例如: nestloop(t1 t2) nestloop(t1 t2)。
-
hint冲突是指,table list一样的hint,存在不一样的hint,hint的冲突仅对于每一类hint方法检测冲突。
例如: nestloop (t1 t2) hashjoin (t1 t2),则后面与前面冲突,此时hashjoin的hint失效。注意:nestloop(t1 t2)和no mergejoin(t1 t2)不冲突。
须知:
leading hint中的多个表会进行拆解。例如: leading ((t1 t2 t3))会拆解成: leading((t1 t2)) leading(((t1 t2) t3)),此时如果存在leading((t2 t1)),则两者冲突,后面的会被丢弃。(例外: 指定内外表的hint若与不指定内外表的hint重复,则始终丢弃不指定内外表的hint。)
-
-
子链接提升后hint失效
子链接提升后的hint失效,会给出提示。通常出现在子链接中存在多个表连接的场景。提升后,子链接中的多个表不再作为一个整体出现在join中。
-
列类型不支持重分布
- 对于skew hint来说,目的是为了进行重分布时的调优,所以当hint列的类型不支持重分布时,hint将无效。
-
hint未被使用
- 非等值join使用hashjoin hint或mergejoin hint。
- 不包含索引的表使用indexscan hint或indexonlyscan hint。
- 通常只有在索引列上使用过滤条件才会生成相应的索引路径,全表扫描将不会使用索引,因此使用indexscan hint或indexonlyscan hint将不会使用。
- indexonlyscan只有输出列仅包含索引列才会使用,否则指定时hint不会被使用。
- 多个表存在等值连接时,仅尝试有等值连接条件的表的连接,此时没有关联条件的表之间的路径将不会生成,所以指定相应的leading,join,rows hint将不使用,例如: t1 t2 t3表join,t1和t2, t2和t3有等值连接条件,则t1和t3不会优先连接,leading(t1 t3)不会被使用。
- 生成stream计划时,如果表的分布列与join列相同,则不会生成redistribute的计划;如果不同,且另一表分布列与join列相同,只能生成redistribute的计划,不会生成broadcast的计划,指定相应的hint则不会被使用。
- 如果子链接未被提升,则blockname hint不会被使用。
- 对于skew hint,hint未被使用可能由于:
- 计划中不需要进行重分布。
- hint指定的列为包含分布键。
- hint指定倾斜信息有误或不完整,如对于join优化未指定值。
- 倾斜优化的GUC参数处于关闭状态。
优化器GUC参数的Hint
功能描述
设置本次查询执行内生效的查询优化相关GUC参数。hint的推荐使用场景可以参考各guc参数的说明,此处不作赘述。
语法格式
set(param value)参数说明
-
param表示参数名。
-
value表示参数的取值。
-
目前支持使用Hint设置生效的参数有
-
布尔类:
enable_bitmapscan, enable_hashagg, enable_hashjoin, enable_indexscan, enable_indexonlyscan, enable_material, enable_mergejoin, enable_nestloop, enable_index_nestloop, enable_seqscan, enable_sort, enable_tidscan, partition_iterator_elimination, partition_page_estimation, enable_functional_dependency, var_eq_const_selectivity
-
整形类:
query_dop
-
浮点类:
cost_weight_index, default_limit_rows, seq_page_cost, random_page_cost, cpu_tuple_cost, cpu_index_tuple_cost, cpu_operator_cost, effective_cache_size
-
枚举类型:
try_vector_engine_strategy
-
- 设置不在白名单中的参数,参数取值不合法,或hint语法错误时,不会影响查询执行的正确性。使用explain(verbose on)执行可以看到hint解析错误的报错提示。
- GUC参数的hint只在最外层查询生效——子查询内的GUC参数hint不生效。
- 视图定义内的GUC参数hint不生效。
- CREATE TABLE … AS … 查询最外层的GUC参数hint可以生效。
Custom Plan和Generic Plan选择的Hint
功能描述
对于以PBE方式执行的查询语句和DML语句,优化器会基于规则、代价、参数等因素选择生成Custom Plan或Generic Plan执行。用户可以通过use_cplan/use_gplan的hint指定使用哪种计划执行方式。
语法格式
-
指定使用Custom Plan:
use_cplan -
指定使用Generic Plan:
use_gplan
- 对于非PBE方式执行的SQL语句,设置本hint不会影响执行方式。
- 本Hint的优先级仅高于基于代价的选择和plan_cache_mode参数,即plan_cache_mode无法强制选择执行方式的语句本hint也无法生效。
示例
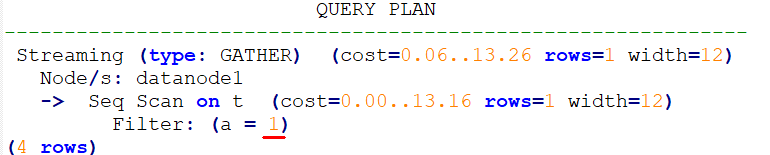
强制使用Custom Plan
create table t (a int, b int, c int);
prepare p as select /*+ use_cplan */ * from t where a = $1;
explain execute p(1);计划如下。可以看到过滤条件为入参的实际值,即此计划为Custom Plan。
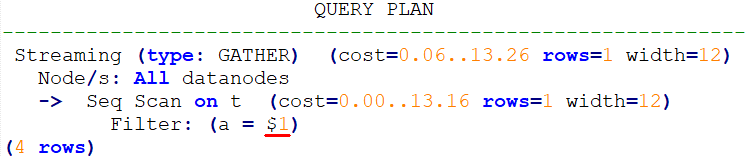
强制使用Generic Plan
deallocate p;
prepare p as select /*+ use_gplan */ * from t where a = $1;
explain execute p(1);计划如下。可以看到过滤条件为待填充的入参,即此计划为Generic Plan。
指定子查询不展开的Hint
功能描述
数据库在对查询进行逻辑优化时通常会将可以提升的子查询提升到上层来避免嵌套执行,但对于某些本身选择率较低且可以使用索引过滤访问页面的子查询,嵌套执行不会导致性能下降过多,而提升之后扩大了查询路径的搜索范围,可能导致性能变差。对于此类情况,可以使用no_expand Hint进行调试。大多数情况下不建议使用此hint。
语法格式
no_expand示例
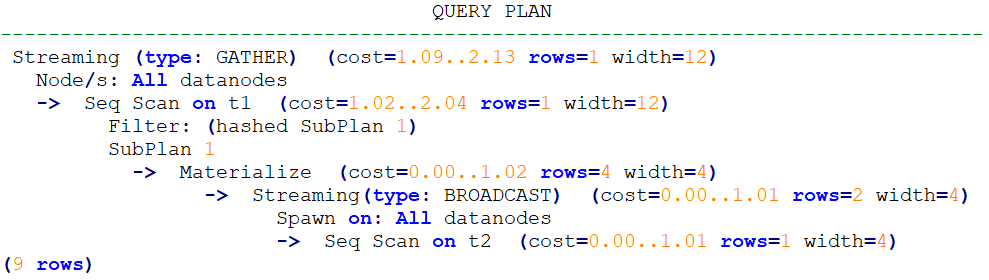
正常的查询执行
explain select * from t1 where t1.a in (select t2.a from t2);计划

加入no_expand
explain select * from t1 where t1.a in (select /*+ no_expand*/ t2.a from t2);计划
指定不使用全局计划缓存的Hint
功能描述
全局计划缓存打开时,可以通过no_gpc Hint来强制单个查询语句不在全局共享计划缓存,只保留会话生命周期的计划缓存。
语法格式
no_gpc
示例

dbe_perf.global_plancache_status视图中无结果即没有计划被全局缓存。
同层参数化路径的Hint
功能描述
通过predpush_same_level Hint来指定同层表或物化视图之间参数化路径生成。
语法格式
predpush_same_level(src, dest)
predpush_same_level(src1 src2 ..., dest)说明: 本参数仅在rewrite_rule中的predpushforce选项打开时生效。
示例
准备参数和表及索引:
MogDB=# set rewrite_rule = 'predpushforce';
SET
MogDB=# create table t1(a int, b int);
CREATE TABLE
MogDB=# create table t2(a int, b int);
CREATE TABLE
MogDB=# create index idx1 on t1(a);
CREATE INDEX
MogDB=# create index idx2 on t2(a);
CREATE INDEX执行语句查看计划:
MogDB=# explain select * from t1, t2 where t1.a = t2.a;
QUERY PLAN
------------------------------------------------------------------
Hash Join (cost=27.50..56.25 rows=1000 width=16)
Hash Cond: (t1.a = t2.a)
-> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)可以看到t1.a = t2.a条件过滤在Join上面,此时可以通过predpush_same_level(t1, t2)将条件下推至t2的扫描算子上:
MogDB=# explain select /*+predpush_same_level(t1, t2)*/ * from t1, t2 where t1.a = t2.a;
QUERY PLAN
---------------------------------------------------------------------
Nested Loop (cost=0.00..335.00 rows=1000 width=16)
-> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
-> Index Scan using idx2 on t2 (cost=0.00..0.31 rows=1 width=8)
Index Cond: (a = t1.a)
(4 rows)须知:
- predpush_same_level可以指定多个src,但是所有的src必须在同一个条件中。
- 如果指定的src和dest条件不存在,或该条件不符合参数化路径要求,则本hint不生效。
不同层参数化路径的Hint
功能描述
通过predpush Hint来指定不同层表或物化视图之间参数化路径生成。
语法格式
predpush(src, dest)
predpush(src1 src2 ..., dest)说明:本参数仅在rewrite_rule中的predpushforce选项打开时生效。
示例
准备参数和表及索引:
MogDB=# set rewrite_rule = 'predpushforce';
SET
MogDB=# create table t1(a int, b int);
CREATE TABLE
MogDB=# create table t2(a int, b int);
CREATE TABLE
MogDB=# create index idx1 on t1(a);
CREATE INDEX
MogDB=# create index idx2 on t2(a);
CREATE INDEX执行语句查看计划:
MogDB=# explain select * from t1,(select a, b, min(a) from t2 group by 1,2) ts where t1.a = ts.a;
QUERY PLAN
------------------------------------------------------------------------
Hash Join (cost=55.38..120.60 rows=2568 width=20)
Hash Cond: (t1.a = t2.a)
-> Seq Scan on t1 (cost=0.00..31.49 rows=2149 width=8)
-> Hash (cost=52.39..52.39 rows=239 width=12)
-> HashAggregate (cost=47.61..50.00 rows=239 width=12)
Group By Key: t2.a, t2.b
-> Seq Scan on t2 (cost=0.00..31.49 rows=2149 width=8)
(7 rows)可以看到t1.a = t2.a条件过滤在Join上面,此时可以通过predpush(t1, ts)将条件下推至t2的扫描算子上:
MogDB=# explain select /*+ predpush(t1, ts) */ * from t1,(select a, b, min(a) from t2 group by 1,2) ts where t1.a = ts.a;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=15.09..32586.69 rows=21 width=20)
-> Seq Scan on t1 (cost=0.00..31.49 rows=2149 width=8)
-> HashAggregate (cost=15.09..15.11 rows=2 width=12)
Group By Key: t2.a, t2.b
-> Bitmap Heap Scan on t2 (cost=4.34..15.01 rows=11 width=8)
Recheck Cond: (t1.a = a)
-> Bitmap Index Scan on idx2 (cost=0.00..4.33 rows=11 width=0)
Index Cond: (t1.a = a)
(8 rows)将部分Error降级为Warning的Hint
功能描述
指定执行INSERT、UPDATE语句时可将部分Error降级为Warning,且不影响语句执行完成的hint。
该hint不支持列存表,无法在列存表中生效。
与其他hint不同,此hint仅影响执行器遇到部分Error时的处理方式,不会对执行计划有任何影响。
使用该hint时,Error会被降级的场景有:
-
违反非空约束时
若执行的SQL语句违反了表的非空约束,使用此hint可将Error降级为Warning,并根据GUC参数sql_ignore_strategy的值采用以下策略的一种继续执行:
-
sql_ignore_startegy为ignore_null时,忽略违反非空约束的行的INSERT/UPDATE操作,并继续执行剩余数据操作。
-
sql_ignore_startegy为overwrite_null时,将违反约束的null值覆写为目标类型的默认值,并继续执行剩余数据操作。
说明:GUC参数sql_ignore_strategy相关信息请参考sql_ignore_strategy。
-
-
违反唯一约束时
若执行的SQL语句违反了表的唯一约束,使用此hint可将Error降级为Warning,忽略违反约束的行的INSERT/UPDATE操作,并继续执行剩余数据操作。
-
分区表无法匹配到合法分区时
在对分区表进行INSERT/UPDATE操作时,若某行数据无法匹配到表格的合法分区,使用此hint可将Error降级为Warning,忽略该行操作,并继续执行剩余数据操作。
-
更新/插入值向目标列类型转换失败时
执行INSERT/UPDATE语句时,若发现新值与目标列类型不匹配,使用此hint可将Error降级为Warning,并根据新值与目标列的具体类型采取以下策略的一种继续执行:
-
当新值类型与列类型同为数值类型时:
若新值在列类型的范围内,则直接进行插入/更新;若新值在列类型范围外,则以列类型的最大/最小值替代。
-
当新值类型与列类型同为字符串类型时:
若新值长度在列类型限定范围内,则以直接进行插入/更新;若新值长度在列类型的限定范围外,则保留列类型长度限制的前n个字符。
-
若遇到新值类型与列类型不可转换时:
插入/更新列类型的默认值。
-
语法格式
ignore_error示例
为使用ignore_error hint,需要创建B兼容模式的数据库,名称为db_ignore。
create database db_ignore dbcompatibility 'B';
\c db_ignore- 忽略非空约束
db_ignore=# create table t_not_null(num int not null);
CREATE TABLE
-- 采用忽略策略
db_ignore=# set sql_ignore_strategy = 'ignore_null';
SET
db_ignore=# insert /*+ ignore_error */ into t_not_null values(null), (1);
WARNING: null value in column "num" violates not-null constraint
DETAIL: Failing row contains (null).
INSERT 0 1
db_ignore=# select * from t_not_null ;
num
-----
1
(1 row)
db_ignore=# update /*+ ignore_error */ t_not_null set num = null where num = 1;
WARNING: null value in column "num" violates not-null constraint
DETAIL: Failing row contains (null).
UPDATE 0
db_ignore=# select * from t_not_null ;
num
-----
1
(1 row)
-- 采用覆写策略
db_ignore=# delete from t_not_null;
db_ignore=# set sql_ignore_strategy = 'overwrite_null';
SET
db_ignore=# insert /*+ ignore_error */ into t_not_null values(null), (1);
WARNING: null value in column "num" violates not-null constraint
DETAIL: Failing row contains (null).
INSERT 0 2
db_ignore=# select * from t_not_null ;
num
-----
0
1
(2 rows)
db_ignore=# update /*+ ignore_error */ t_not_null set num = null where num = 1;
WARNING: null value in column "num" violates not-null constraint
DETAIL: Failing row contains (null).
UPDATE 1
db_ignore=# select * from t_not_null ;
num
-----
0
0
(2 rows)- 忽略唯一约束
db_ignore=# create table t_unique(num int unique);
NOTICE: CREATE TABLE / UNIQUE will create implicit index "t_unique_num_key" for table "t_unique"
CREATE TABLE
db_ignore=# insert into t_unique values(1);
INSERT 0 1
db_ignore=# insert /*+ ignore_error */ into t_unique values(1),(2);
WARNING: duplicate key value violates unique constraint in table "t_unique"
INSERT 0 1
db_ignore=# select * from t_unique;
num
-----
1
2
(2 rows)
db_ignore=# update /*+ ignore_error */ t_unique set num = 1 where num = 2;
WARNING: duplicate key value violates unique constraint in table "t_unique"
UPDATE 0
db_ignore=# select * from t_unique ;
num
-----
1
2
(2 rows)- 忽略分区表无法匹配到合法分区
db_ignore=# CREATE TABLE t_ignore
db_ignore-# (
db_ignore(# col1 integer NOT NULL,
db_ignore(# col2 character varying(60)
db_ignore(# ) WITH(segment = on) PARTITION BY RANGE (col1)
db_ignore-# (
db_ignore(# PARTITION P1 VALUES LESS THAN(5000),
db_ignore(# PARTITION P2 VALUES LESS THAN(10000),
db_ignore(# PARTITION P3 VALUES LESS THAN(15000)
db_ignore(# );
CREATE TABLE
db_ignore=# insert /*+ ignore_error */ into t_ignore values(20000);
WARNING: inserted partition key does not map to any table partition
INSERT 0 0
db_ignore=# select * from t_ignore ;
col1 | col2
------+------
(0 rows)
db_ignore=# insert into t_ignore values(3000);
INSERT 0 1
db_ignore=# select * from t_ignore ;
col1 | col2
------+------
3000 |
(1 row)
db_ignore=# update /*+ ignore_error */ t_ignore set col1 = 20000 where col1 = 3000;
WARNING: fail to update partitioned table "t_ignore".new tuple does not map to any table partition.
UPDATE 0
db_ignore=# select * from t_ignore ;
col1 | col2
------+------
3000 |
(1 row)
- 更新/插入值向目标列类型转换失败
-- 当新值类型与列类型同为数值类型
db_ignore=# create table t_tinyint(num tinyint);
CREATE TABLE
db_ignore=# insert /*+ ignore_error */ into t_tinyint values(10000);
WARNING: tinyint out of range
CONTEXT: referenced column: num
INSERT 0 1
db_ignore=# select * from t_tinyint;
num
-----
255
(1 row)
-- 当新值类型与列类型同为字符类型时
db_ignore=# create table t_varchar5(content varchar(5));
CREATE TABLE
db_ignore=# insert /*+ ignore_error */ into t_varchar5 values('abcdefghi');
WARNING: value too long for type character varying(5)
CONTEXT: referenced column: content
INSERT 0 1
db_ignore=# select * from t_varchar5 ;
content
---------
abcde
(1 row)