v3.1
- 关于MogDB
- 快速入门
- MogDB实训平台
- 容器化安装
- 单节点安装
- 访问数据库
- 使用命令行访问MogDB
- 使用图形工具访问MogDB
- 使用中间件访问MogDB
- 使用编程语言访问MogDB
- 使用样本数据集Mogila
- 特性描述
- 概览
- 高性能
- 高可用
- 维护性
- 数据库安全
- 企业级特性
- 应用开发接口
- AI能力
- AI4DB:数据库自治运维
- DB4AI:数据库驱动AI
- AI in DB:数据库内AI功能
- ABO优化器
- 中间件
- 安装指南
- 管理指南
- 本地化
- 日常运维
- 主备管理
- MOT内存表管理
- 列存表管理
- 备份与恢复
- 两地三中心跨Region容灾
- 数据导出导入
- 升级指南
- AI特性指南
- AI特性概述
- AI4DB:数据库自治运维
- DBMind模式说明
- DBMind的支持组件
- DBMind的AI子功能
- DB4AI:数据库驱动AI
- AI in DB:数据库内AI功能
- ABO 优化器
- 安全指南
- 开发者指南
- 应用程序开发教程
- 开发规范
- 基于JDBC开发
- 概述
- JDBC包、驱动类和环境类
- 开发流程
- 加载驱动
- 连接数据库
- 连接数据库(以SSL方式)
- 连接数据库(UDS方式)
- 执行SQL语句
- 处理结果集
- 关闭连接
- 日志管理
- 示例:常用操作
- 示例:重新执行应用SQL
- 示例:通过本地文件导入导出数据
- 示例:从MY向MogDB进行数据迁移
- 示例:逻辑复制代码示例
- 示例:不同场景下连接数据库参数配置
- JDBC接口参考
- java.sql.Connection
- java.sql.CallableStatement
- java.sql.DatabaseMetaData
- java.sql.Driver
- java.sql.PreparedStatement
- java.sql.ResultSet
- java.sql.ResultSetMetaData
- java.sql.Statement
- javax.sql.ConnectionPoolDataSource
- javax.sql.DataSource
- javax.sql.PooledConnection
- javax.naming.Context
- javax.naming.spi.InitialContextFactory
- CopyManager
- JDBC常用参数参考
- 基于ODBC开发
- 基于libpq开发
- libpq使用依赖的头文件
- 开发流程
- 示例
- 链接参数
- libpq接口参考
- 数据库连接控制函数
- 数据库执行语句函数
- 异步命令处理
- 取消正在处理的查询
- 基于Psycopg开发
- 调试
- 存储过程
- 用户自定义函数
- PL/pgSQL-SQL过程语言
- 定时任务
- 自治事务
- 逻辑复制
- Extension
- PostGIS Extension
- Foreign Data Wrapper
- orafce
- pg_bulkload
- pg_prewarm
- pg_repack
- pg_trgm
- wal2json
- whale
- 物化视图
- 分区管理
- 应用程序开发教程
- 性能优化指南
- 参考指南
- 系统表及系统视图
- 系统表和系统视图概述
- 系统表
- GS_ASP
- GS_AUDITING_POLICY
- GS_AUDITING_POLICY_ACCESS
- GS_AUDITING_POLICY_FILTERS
- GS_AUDITING_POLICY_PRIVILEGES
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_DB_PRIVILEGE
- GS_ENCRYPTED_COLUMNS
- GS_ENCRYPTED_PROC
- GS_GLOBAL_CHAIN
- GS_GLOBAL_CONFIG
- GS_MASKING_POLICY
- GS_MASKING_POLICY_ACTIONS
- GS_MASKING_POLICY_FILTERS
- GS_MATVIEW
- GS_MATVIEW_DEPENDENCY
- GS_MODEL_WAREHOUSE
- GS_OPT_MODEL
- GS_PACKAGE
- GS_POLICY_LABEL
- GS_RECYCLEBIN
- GS_TXN_SNAPSHOT
- GS_UID
- GS_WLM_EC_OPERATOR_INFO
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_SESSION_QUERY_INFO_ALL
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_AUTHID
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_HASHBUCKET
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_PUBLICATION
- PG_PUBLICATION_REL
- PG_RANGE
- PG_REPLICATION_ORIGIN
- PG_RESOURCE_POOL
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SET
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SUBSCRIPTION
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PGXC_SLICE
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- 系统视图
- DV_SESSION_LONGOPS
- DV_SESSIONS
- GET_GLOBAL_PREPARED_XACTS(废弃)
- GS_AUDITING
- GS_AUDITING_ACCESS
- GS_AUDITING_PRIVILEGE
- GS_ASYNC_SUBMIT_SESSIONS_STATUS
- GS_CLUSTER_RESOURCE_INFO
- GS_COMPRESSION
- GS_DB_PRIVILEGES
- GS_FILE_STAT
- GS_GSC_MEMORY_DETAIL
- GS_INSTANCE_TIME
- GS_LABELS
- GS_LSC_MEMORY_DETAIL
- GS_MASKING
- GS_MATVIEWS
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY
- GS_SESSION_MEMORY_CONTEXT
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_MEMORY_STATISTICS
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_SQL_COUNT
- GS_STAT_SESSION_CU
- GS_THREAD_MEMORY_CONTEXT
- GS_TOTAL_MEMORY_DETAIL
- GS_WLM_CGROUP_INFO
- GS_WLM_EC_OPERATOR_STATISTICS
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_INFO_ALL
- GS_WLM_SESSION_STATISTICS
- GS_WLM_USER_INFO
- GS_WRITE_TERM_LOG
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_COMM_DELAY
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_STATUS
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_ATTACHED_PIDS
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_INDEXES
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_PUBLICATION_TABLES
- PG_REPLICATION_ORIGIN_STATUS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SESSION_IOSTAT
- PG_SESSION_WLMSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_STAT_ACTIVITY
- PG_STAT_ACTIVITY_NG
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_REPLICATION
- PG_STAT_SUBSCRIPTION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_STATS
- PG_TABLES
- PG_TDE_INFO
- PG_THREAD_WAIT_STATUS
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_USER_RESOURCE_INFO
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_USER
- PG_USER_MAPPINGS
- PG_VARIABLE_INFO
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_PREPARED_XACTS
- PLAN_TABLE
- 系统函数
- 逻辑操作符
- 比较操作符
- 字符处理函数和操作符
- 二进制字符串函数和操作符
- 位串函数和操作符
- 模式匹配操作符
- 数字操作函数和操作符
- 时间和日期处理函数和操作符
- 类型转换函数
- 几何函数和操作符
- 网络地址函数和操作符
- 文本检索函数和操作符
- JSON/JSONB函数和操作符
- HLL函数和操作符
- SEQUENCE函数
- 数组函数和操作符
- 范围函数和操作符
- 聚集函数
- 窗口函数(分析函数)
- 安全函数
- 账本数据库的函数
- 密态等值的函数
- 返回集合的函数
- 条件表达式函数
- 系统信息函数
- 系统管理函数
- 统计信息函数
- 触发器函数
- HashFunc函数
- 提示信息函数
- 全局临时表函数
- 故障注入系统函数
- AI特性函数
- 动态数据脱敏函数
- 其他系统函数
- 内部函数
- Global SysCache特性函数
- 数据损坏检测修复函数
- 废弃函数
- 支持的数据类型
- SQL语法
- ABORT
- ALTER AGGREGATE
- ALTER AUDIT POLICY
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER EXTENSION
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GLOBAL CONFIGURATION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MASKING POLICY
- ALTER MATERIALIZED VIEW
- ALTER PACKAGE
- ALTER PROCEDURE
- ALTER PUBLICATION
- ALTER RESOURCE LABEL
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SUBSCRIPTION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLE SUBPARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- CONNECT BY
- COPY
- CREATE AGGREGATE
- CREATE AUDIT POLICY
- CREATE CAST
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE EXTENSION
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INCREMENTAL MATERIALIZED VIEW
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MASKING POLICY
- CREATE MATERIALIZED VIEW
- CREATE MODEL
- CREATE OPERATOR
- CREATE PACKAGE
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE RESOURCE LABEL
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE ROW LEVEL SECURITY POLICY
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SUBSCRIPTION
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLE SUBPARTITION
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CREATE WEAK PASSWORD DICTIONARY
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DO
- DROP AGGREGATE
- DROP AUDIT POLICY
- DROP CAST
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP EXTENSION
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GLOBAL CONFIGURATION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MASKING POLICY
- DROP MATERIALIZED VIEW
- DROP MODEL
- DROP OPERATOR
- DROP OWNED
- DROP PACKAGE
- DROP PROCEDURE
- DROP PUBLICATION
- DROP RESOURCE LABEL
- DROP RESOURCE POOL
- DROP ROLE
- DROP ROW LEVEL SECURITY POLICY
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SUBSCRIPTION
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- DROP WEAK PASSWORD DICTIONARY
- EXECUTE
- EXECUTE DIRECT
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MERGE INTO
- MOVE
- PREDICT BY
- PREPARE
- PREPARE TRANSACTION
- PURGE
- REASSIGN OWNED
- REFRESH INCREMENTAL MATERIALIZED VIEW
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHUTDOWN
- SNAPSHOT
- START TRANSACTION
- TIMECAPSULE TABLE
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- SHRINK
- SQL参考
- GUC参数说明
- Schema
- 概述
- Information Schema
- DBE_PERF
- 概述
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- LOCAL_ACTIVE_SESSION
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- GLOBAL_SINGLE_FLUSH_DW_STATUS
- GLOBAL_CANDIDATE_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- RTO
- DBE_PLDEBUGGER Schema
- DBE_PLDEBUGGER Schema概述
- DBE_PLDEBUGGER.turn_on
- DBE_PLDEBUGGER.turn_off
- DBE_PLDEBUGGER.local_debug_server_info
- DBE_PLDEBUGGER.attach
- DBE_PLDEBUGGER.info_locals
- DBE_PLDEBUGGER.next
- DBE_PLDEBUGGER.continue
- DBE_PLDEBUGGER.abort
- DBE_PLDEBUGGER.print_var
- DBE_PLDEBUGGER.info_code
- DBE_PLDEBUGGER.step
- DBE_PLDEBUGGER.add_breakpoint
- DBE_PLDEBUGGER.delete_breakpoint
- DBE_PLDEBUGGER.info_breakpoints
- DBE_PLDEBUGGER.backtrace
- DBE_PLDEBUGGER.disable_breakpoint
- DBE_PLDEBUGGER.enable_breakpoint
- DBE_PLDEBUGGER.finish
- DBE_PLDEBUGGER.set_var
- DB4AI Schema
- DBE_PLDEVELOPER
- 工具参考
- 数据库报错信息
- SQL标准错误码说明
- 第三方库错误码说明
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07480
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53799
- 错误日志信息参考
- 系统表及系统视图
- 故障诊断指南
- 常见故障定位手段
- 常见故障定位案例
- core问题定位
- 权限/会话/数据类型问题定位
- 服务/高可用/并发问题定位
- 表/分区表问题定位
- 文件系统/磁盘/内存问题定位
- SQL问题定位
- 索引问题定位
- CM两节点故障问题定位
- 源码解析
- 常见问题解答 (FAQs)
- 术语表
- 通信矩阵
- Mogeaver
行列混合存储
可获得性
本特性自MogDB 1.1.0版本开始引入。
特性简介
MogDB支持行存储和列存储两种存储模型,用户可以根据具体的使用场景,建表时选择行存储还是列存储表。
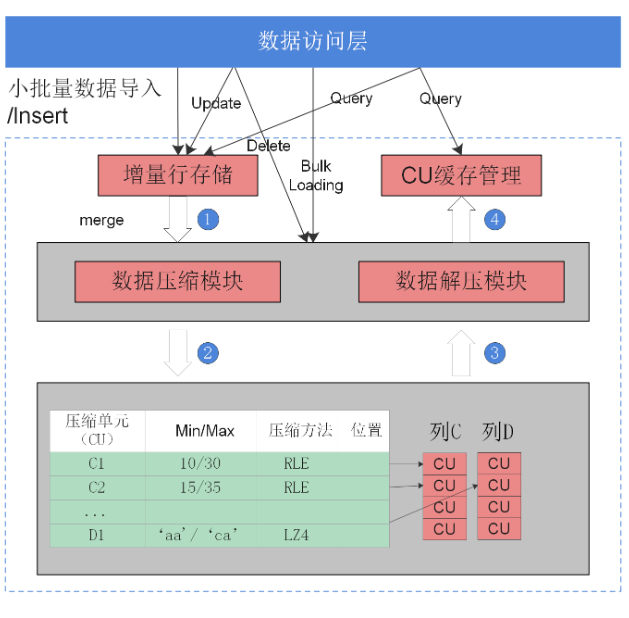
一般情况下,如果表的字段比较多(即大宽表),查询中涉及到列不很多的情况下,适合列存储。列存储方式如图1所示。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
图 1 列存储示意图
客户价值
在大宽表、数据量比较大的场景中,查询经常关注某些列,行存储引擎查询性能比较差。例如,气象局的场景,单表有200~800个列,查询经常访问10个列,在类似这样的场景下,向量化执行技术和列存储引擎可以极大的提升性能和减少存储空间。
特性描述
表有行存表和列存表两种存储模型。两种存储模型各有优劣,建议根据实际情况选择。
-
行存表
默认创建表的类型。数据按行进行存储,即一行数据紧挨着存储。行存表支持完整的增删改查。适用于对数据需要经常更新的场景。
-
列存表
数据按列进行存储,即一列所有数据紧挨着存储。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询,insert插入单条记录性能差。
-
行存表和列存表的选择依据如下:
-
更新频繁程度
数据如果频繁更新,选择行存表。
-
插入频繁程度、
频繁的少量插入,选择行存表。一次插入大批量数据,选择列存表。
-
表的列数
表的列数很多,选择列存表。
-
查询的列数
如果每次查询时,只涉及了表的少数(小于总列数的50%)几个列,选择列存表。
-
压缩率
列存表比行存表压缩率高。但高压缩率会消耗更多的CPU资源。
-
特性增强
无。
特性约束
无。
依赖关系
无。