- 关于MogDB
- 快速入门
- MogDB实训平台
- 容器化安装
- 单节点安装
- 访问数据库
- 使用命令行访问MogDB
- 使用图形工具访问MogDB
- 使用中间件访问MogDB
- 使用编程语言访问MogDB
- 使用样本数据集Mogila
- 特性描述
- 高性能
- 高可用
- 维护性
- 数据库安全
- 企业级特性
- 应用开发接口
- AI能力
- 安装指南
- 管理指南
- AI特性指南
- 概述
- Predictor:AI查询时间预测
- X-Tuner:参数调优与诊断
- SQLdiag:慢SQL发现
- Anomaly-detection:数据库指标采集、预测与异常监控
- Index-advisor:索引推荐
- DeepSQL:库内AI算法
- DB4AI:数据库原生AI引擎
- 安全指南
- 开发者指南
- 应用程序开发教程
- 开发规范
- 基于JDBC开发
- 概述
- JDBC包、驱动类和环境类
- 开发流程
- 加载驱动
- 连接数据库
- 连接数据库(以SSL方式)
- 执行SQL语句
- 处理结果集
- 关闭连接
- 日志管理
- 示例:常用操作
- 示例:重新执行应用SQL
- 示例:通过本地文件导入导出数据
- 示例:从MY向MogDB进行数据迁移
- 示例:逻辑复制代码示例
- 示例:不同场景下连接数据库参数配置
- JDBC接口参考
- java.sql.Connection
- java.sql.CallableStatement
- java.sql.DatabaseMetaData
- java.sql.Driver
- java.sql.PreparedStatement
- java.sql.ResultSet
- java.sql.ResultSetMetaData
- java.sql.Statement
- javax.sql.ConnectionPoolDataSource
- javax.sql.DataSource
- javax.sql.PooledConnection
- javax.naming.Context
- javax.naming.spi.InitialContextFactory
- CopyManager
- 基于ODBC开发
- 基于libpq开发
- 基于Psycopg开发
- 调试
- 附录
- 存储过程
- 用户自定义函数
- PL/pgSQL-SQL过程语言
- 定时任务
- 自治事务
- 逻辑复制
- Foreign Data Wrapper
- 物化视图
- 资源负载管理
- 应用程序开发教程
- 性能优化指南
- 参考指南
- 系统表及系统视图
- 系统表和系统视图概述
- 系统表
- GS_AUDITING_POLICY
- GS_AUDITING_POLICY_ACCESS
- GS_AUDITING_POLICY_FILTERS
- GS_AUDITING_POLICY_PRIVILEGES
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_ENCRYPTED_COLUMNS
- GS_ENCRYPTED_PROC
- GS_GLOBAL_CHAIN
- GS_MASKING_POLICY
- GS_MASKING_POLICY_ACTIONS
- GS_MASKING_POLICY_FILTERS
- GS_MATVIEW
- GS_MATVIEW_DEPENDENCY
- GS_OPT_MODEL
- GS_POLICY_LABEL
- GS_RECYCLEBIN
- GS_TXN_SNAPSHOT
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_EC_OPERATOR_INFO
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTHID
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_RANGE
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- 系统视图
- GET_GLOBAL_PREPARED_XACTS(废弃)
- GS_AUDITING
- GS_AUDITING_ACCESS
- GS_AUDITING_PRIVILEGE
- GS_CLUSTER_RESOURCE_INFO
- GS_INSTANCE_TIME
- GS_LABELS
- GS_MASKING
- GS_MATVIEWS
- GS_SESSION_MEMORY
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY_CONTEXT
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_MEMORY_STATISTICS
- GS_SQL_COUNT
- GS_WLM_CGROUP_INFO
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_USER_INFO
- GS_STAT_SESSION_CU
- GS_TOTAL_MEMORY_DETAIL
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_COMM_DELAY
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_STATUS
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_GTT_ATTACHED_PIDS
- PG_INDEXES
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_SECLABELS
- PG_SETTINGS
- PG_SHADOW
- PG_STATS
- PG_STAT_ACTIVITY
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_REPLICATION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_TABLES
- PG_TDE_INFO
- PG_THREAD_WAIT_STATUS
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_USER_RESOURCE_INFO
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_USER
- PG_USER_MAPPINGS
- PG_VARIABLE_INFO
- PG_VIEWS
- PLAN_TABLE
- GS_FILE_STAT
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_THREAD_MEMORY_CONTEXT
- 系统函数
- 支持的数据类型
- SQL语法
- ABORT
- ALTER AGGREGATE
- ALTER AUDIT POLICY
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER EXTENSION
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MASKING POLICY
- ALTER MATERIALIZED VIEW
- ALTER OPERATOR
- ALTER RESOURCE LABEL
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLE SUBPARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- CONNECT BY
- COPY
- CREATE AGGREGATE
- CREATE AUDIT POLICY
- CREATE CAST
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE EXTENSION
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INCREMENTAL MATERIALIZED VIEW
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MASKING POLICY
- CREATE MATERIALIZED VIEW
- CREATE MODEL
- CREATE OPERATOR
- CREATE PACKAGE
- CREATE ROW LEVEL SECURITY POLICY
- CREATE PROCEDURE
- CREATE RESOURCE LABEL
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLE SUBPARTITION
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CREATE WEAK PASSWORD DICTIONARY
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DO
- DROP AGGREGATE
- DROP AUDIT POLICY
- DROP CAST
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP EXTENSION
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MASKING POLICY
- DROP MATERIALIZED VIEW
- DROP MODEL
- DROP OPERATOR
- DROP OWNED
- DROP PACKAGE
- DROP PROCEDURE
- DROP RESOURCE LABEL
- DROP RESOURCE POOL
- DROP ROW LEVEL SECURITY POLICY
- DROP ROLE
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- DROP WEAK PASSWORD DICTIONARY
- EXECUTE
- EXECUTE DIRECT
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MOVE
- MERGE INTO
- PREDICT BY
- PREPARE
- PREPARE TRANSACTION
- PURGE
- REASSIGN OWNED
- REFRESH INCREMENTAL MATERIALIZED VIEW
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHUTDOWN
- SNAPSHOT
- START TRANSACTION
- TIMECAPSULE TABLE
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- SQL参考
- GUC参数说明
- Schema
- Information Schema
- DBE_PERF
- 概述
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- LOCAL_ACTIVE_SESSION
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_USER_COMPLEX_HISTORY
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- GLOBAL_SINGLE_FLUSH_DW_STATUS
- GLOBAL_CANDIDATE_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- RTO
- 附录
- DBE_PLDEBUGGER Schema
- DBE_PLDEBUGGER Schema概述
- DBE_PLDEBUGGER.turn_on
- DBE_PLDEBUGGER.turn_off
- DBE_PLDEBUGGER.local_debug_server_info
- DBE_PLDEBUGGER.attach
- DBE_PLDEBUGGER.next
- DBE_PLDEBUGGER.continue
- DBE_PLDEBUGGER.abort
- DBE_PLDEBUGGER.print_var
- DBE_PLDEBUGGER.info_code
- DBE_PLDEBUGGER.step
- DBE_PLDEBUGGER.add_breakpoint
- DBE_PLDEBUGGER.delete_breakpoint
- DBE_PLDEBUGGER.info_breakpoints
- DBE_PLDEBUGGER.backtrace
- DBE_PLDEBUGGER.finish
- DBE_PLDEBUGGER.set_var
- DB4AI Schema
- 工具参考
- 工具一览表
- 客户端工具
- 服务端工具
- 系统内部使用的工具
- mogdb
- gs_backup
- gs_basebackup
- gs_ctl
- gs_initdb
- gs_install
- gs_install_plugin
- gs_install_plugin_local
- gs_preinstall
- gs_sshexkey
- gs_tar
- gs_uninstall
- gs_upgradectl
- gs_expansion
- gs_dropnode
- gs_probackup
- gstrace
- kdb5_util
- kadmin.local
- kinit
- klist
- krb5kdc
- kdestroy
- pg_config
- pg_controldata
- pg_recvlogical
- pg_resetxlog
- pg_archivecleanup
- pssh
- pscp
- transfer.py
- FAQ
- gs_collector工具支持收集的系统表和视图列表
- 插件
- 数据库报错信息
- SQL标准错误码说明
- 第三方库错误码说明
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07480
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53699
- 错误日志信息参考
- 系统表及系统视图
- 故障诊断指南
- 常见故障定位手段
- 常见故障定位案例
- core问题定位
- 权限/会话/数据类型问题定位
- 服务/高可用/并发问题定位
- 表/分区表问题定位
- 文件系统/磁盘/内存问题定位
- SQL问题定位
- 索引问题定位
- 源码解析
- 常见问题解答 (FAQs)
- 术语表
使用示例
X-Tuner 支持三种模式,分别是获取参数诊断报告的recommend模式、训练强化学习模型的train模式、以及使用算法进行调优的tune模式。上述三种模式可以通过命令行参数来区别,通过配置文件来指定具体的细节。
配置数据库连接信息
三种模式连接数据库的配置项是相同的,有两种方式:一种是直接通过命令行输入详细的连接信息,另一种是通过JSON格式的配置文件输入,下面分别对两种指定数据库连接信息的方法进行说明。
-
通过命令行指定:
分别传递 -db-name -db-user -port -host -host-user 参数,可选 -host-ssh-port 参数,例如:
gs_xtuner recommend --db-name mogdb --db-user omm --port 5678 --host 192.168.1.100 --host-user omm -
通过JSON格式的连接信息配置文件指定:
JSON配置文件的示例如下,并假设文件名为 connection.json:
{ "db_name": "mogdb", # 数据库名 "db_user": "dba", # 登录到数据库上的用户名 "host": "127.0.0.1", # 数据库宿主机的IP地址 "host_user": "dba", # 登录到数据库宿主机的用户名 "port": 5432, # 数据库的侦听端口号 "ssh_port": 22 # 数据库宿主机的SSH侦听端口号 }则可通过 -f connection.json 传递。
说明: 为了防止密码泄露,配置文件和命令行参数中默认都不包含密码信息,用户在输入上述连接信息后,程序会采用交互式的方式要求用户输数据库密码以及操作系统登录用户的密码。
recommend 模式使用示例
对recommend 模式生效的配置项为 scenario,若为auto,则自动检测workload类型。
执行下述命令,获取诊断结果:
gs_xtuner recommend -f connection.json则可以生成诊断报告如下:
图 1 recommend 模式生成的报告示意图
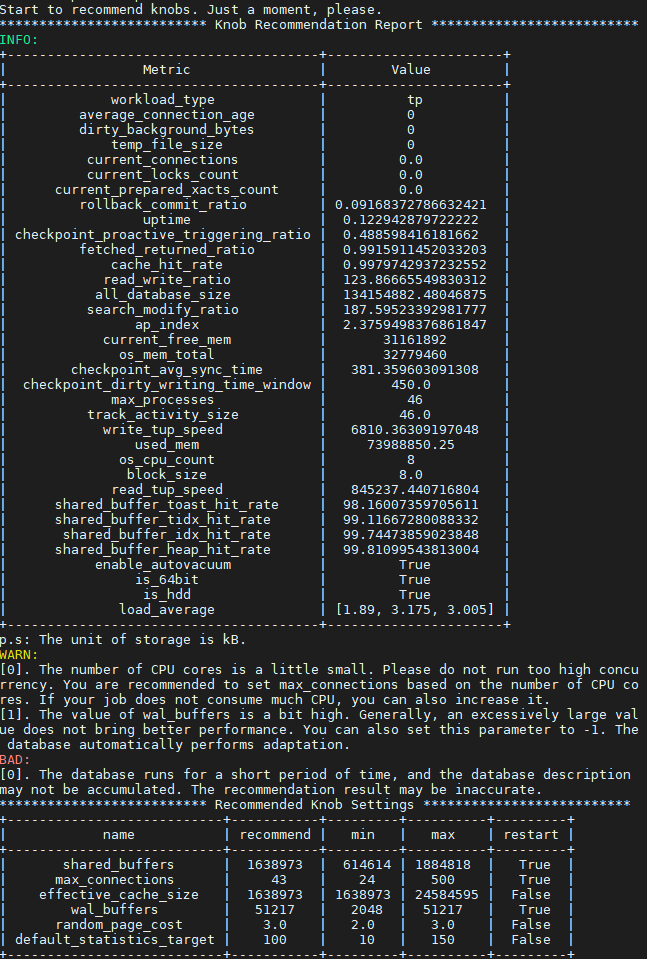
在上述报告中,推荐了该环境上的数据库参数配置,并进行了风险提示。报告同时生成了当前workload的特征信息,其中有几个特征是比较有参考意义的:
- temp_file_size:产生的临时文件数量,如果该结果大于0,则表明系统使用了临时文件。使用过多的临时文件会导致性能不佳,如果可能的话,需要提高work_mem参数的配置。
- cache_hit_rate:shared_buffer 的缓存命中率,表明当前workload使用缓存的效率。
- read_write_ratio:数据库作业的读写比例。
- search_modify_ratio:数据库作业的查询与修改数据的比例。
- ap_index:表明当前workload的AP指数,取值范围是0到10,该数值越大,表明越偏向于数据分析与检索。
- workload_type:根据数据库统计信息,推测当前负载类型,分为AP、TP以及HTAP三种类型。
- checkpoint_avg_sync_time:数据库在checkpoint 时,平均每次同步刷新数据到磁盘的时长,单位是毫秒。
- load_average:平均每个CPU核心在1分钟、5分钟以及15分钟内的负载。一般地,该数值在1左右表明当前硬件比较匹配workload、在3左右表明运行当前作业压力比较大,大于5则表示当前硬件环境运行该workload压力过大(此时一般建议减少负载或升级硬件)。
select pg_stat_reset_shared('bgwriter');
select pg_stat_reset();
train 模式使用示例
该模式是用来训练深度强化学习模型的,与该模式有关的配置项为:
-
rl_algorithm:用于训练强化学习模型的算法,当前支持设置为ddpg。
-
rl_model_path:训练后生成的强化学习模型保存路径。
-
rl_steps:训练过程的最大迭代步数。
-
max_episode_steps:每个回合的最大步数。
-
scenario:明确指定的workload类型,如果为auto则为自动判断。在不同模式下,推荐的调优参数列表也不一样。
-
tuning_list:**用户指定需要调哪些参数,如果不指定,则根据workload类型自动推荐应该调的参数列表。**如需指定,则tuning_list 表示调优列表文件的路径。一个调优列表配置文件的文件内容示例如下:
{ "work_mem": { "default": 65536, "min": 65536, "max": 655360, "type": "int", "restart": false }, "shared_buffers": { "default": 32000, "min": 16000, "max": 64000, "type": "int", "restart": true }, "random_page_cost": { "default": 4.0, "min": 1.0, "max": 4.0, "type": "float", "restart": false }, "enable_nestloop": { "default": true, "type": "bool", "restart": false } }
待上述配置项配置完成后,可以通过下述命令启动训练:
gs_xtuner train -f connection.json训练完成后,会在配置项rl_model_path指定的目录中生成模型文件。
tune 模式使用示例
tune模式支持多种算法,包括基于强化学习(Reinforcement Learning, RL)的DDPG算法、基于全局搜索算法(Global OPtimization algorithm, GOP)算法的贝叶斯优化算法(Bayesian Optimization)以及粒子群算法(Particle Swarm Optimization, PSO)。
与tune模式相关的配置项为:
- tune_strategy: 指定选择哪种算法进行调优,支持rl(使用强化学习模型进行调优)、gop (使用全局搜索算法)以及 auto(自动选择)。若该参数设置为rl,则rl相关的配置项生效。除前文提到过的train模式下生效的配置项外,test_episode配置项也生效,该配置项表明调优过程的最大回合数,该参数直接影响了调优过程的执行时间(一般地,数值越大越耗时)。
- gop_algorithm: 选择何种全局搜索算法,支持bayes以及pso。
- max_iterations: 最大迭代轮次,数值越高搜索时间越长,效果往往越好。
- particle_nums: 在PSO算法上生效,表示粒子数。
- scenario 与 tuning_list 见上文 train 模式中的描述。
待上述配置项配置完成后,可以通过下述命令启动调优:
gs_xtuner tune -f connection.json
注意: 在使用tune和train 模式前,用户需要先导入benchmark所需数据并检查benchmark能否正常跑通。调优过程结束后,调优程序会自动恢复调优前的数据库参数配置。