- About MogDB
- Quick Start
- MogDB Playground
- Container-based MogDB Installation
- Installation on a Single Node
- MogDB Access
- Use CLI to Access MogDB
- Use GUI to Access MogDB
- Use Middleware to Access MogDB
- Use Programming Language to Access MogDB
- Using Sample Dataset Mogila
- Characteristic Description
- Overview
- High Performance
- CBO Optimizer
- LLVM
- Vectorized Engine
- Hybrid Row-Column Store
- Adaptive Compression
- SQL by pass
- Kunpeng NUMA Architecture Optimization
- High Concurrency of Thread Pools
- SMP for Parallel Execution
- Xlog no Lock Flush
- Parallel Page-based Redo For Ustore
- Row-Store Execution to Vectorized Execution
- Astore Row Level Compression
- BTree Index Compression
- Tracing SQL Function
- Parallel Index Scan
- Enhancement of Tracing Backend Key Thread
- Ordering Operator Optimization
- High Availability (HA)
- Primary/Standby
- Logical Replication
- Logical Backup
- Physical Backup
- Automatic Job Retry upon Failure
- Ultimate RTO
- High Availability Based on the Paxos Protocol
- Cascaded Standby Server
- Delayed Replay
- Adding or Deleting a Standby Server
- Delaying Entering the Maximum Availability Mode
- Parallel Logical Decoding
- DCF
- CM(Cluster Manager)
- Global SysCache
- Using a Standby Node to Build a Standby Node
- Two City and Three Center DR
- CM Cluster Management Component Supporting Two Node Deployment
- Maintainability
- Database Security
- Access Control Model
- Separation of Control and Access Permissions
- Database Encryption Authentication
- Data Encryption and Storage
- Database Audit
- Network Communication Security
- Resource Label
- Unified Audit
- Dynamic Data Anonymization
- Row-Level Access Control
- Password Strength Verification
- Equality Query in a Fully-encrypted Database
- Ledger Database Mechanism
- Transparent Data Encryption
- Enterprise-Level Features
- Support for Functions and Stored Procedures
- SQL Hints
- Full-Text Indexing
- Copy Interface for Error Tolerance
- Partitioning
- Support for Advanced Analysis Functions
- Materialized View
- HyperLogLog
- Creating an Index Online
- Autonomous Transaction
- Global Temporary Table
- Pseudocolumn ROWNUM
- Stored Procedure Debugging
- JDBC Client Load Balancing and Read/Write Isolation
- In-place Update Storage Engine
- Publication-Subscription
- Foreign Key Lock Enhancement
- Data Compression in OLTP Scenarios
- Transaction Async Submit
- Index Creation Parallel Control
- Dynamic Partition Pruning
- COPY Import Optimization
- SQL Running Status Observation
- BRIN Index
- BLOOM Index
- Application Development Interfaces
- AI Capabilities
- AI4DB: Autonomous Database O&M
- DB4AI: Database-driven AI
- AI in DB
- ABO Optimizer
- Middleware
- Installation Guide
- Installation Preparation
- Container Installation
- PTK-based Installation
- OM-based Installation
- Manual Installation
- Recommended Parameter Settings
- Administrator Guide
- Localization
- Routine Maintenance
- Starting and Stopping MogDB
- Using the gsql Client for Connection
- Routine Maintenance
- Checking OS Parameters
- Checking MogDB Health Status
- Checking Database Performance
- Checking and Deleting Logs
- Checking Time Consistency
- Checking The Number of Application Connections
- Routinely Maintaining Tables
- Routinely Recreating an Index
- Exporting and Viewing the WDR
- Data Security Maintenance Suggestions
- Slow SQL Diagnosis
- Log Reference
- Primary and Standby Management
- MOT Engine
- Introducing MOT
- Using MOT
- Concepts of MOT
- Appendix
- Column-store Tables Management
- Backup and Restoration
- Two City and Three Center DR
- Importing and Exporting Data
- Importing Data
- Exporting Data
- Upgrade Guide
- AI Features Guide
- AI Features Overview
- AI4DB: Autonomous Database O&M
- DBMind Mode
- Components that Support DBMind
- AI Sub-functions of the DBMind
- X-Tuner: Parameter Tuning and Diagnosis
- Index-advisor: Index Recommendation
- Slow Query Diagnosis: Root Cause Analysis for Slow SQL Statements
- Forecast: Trend Prediction
- SQLdiag: Slow SQL Discovery
- SQL Rewriter
- Anomaly Detection
- DB4AI: Database-driven AI
- AI in DB
- Intelligence Explain: SQL Statement Query Time Prediction
- ABO Optimizer
- Intelligent Cardinality Estimation
- Adaptive Plan Selection
- Security Guide
- Developer Guide
- Application Development Guide
- Development Specifications
- Development Based on JDBC
- Overview
- JDBC Package, Driver Class, and Environment Class
- Development Process
- Loading the Driver
- Connecting to a Database
- Connecting to the Database (Using SSL)
- Connecting to the Database (Using UDS)
- Running SQL Statements
- Processing Data in a Result Set
- Closing a Connection
- Managing Logs
- Example: Common Operations
- Example: Retrying SQL Queries for Applications
- Example: Importing and Exporting Data Through Local Files
- Example 2: Migrating Data from a MY Database to MogDB
- Example: Logic Replication Code
- Example: Parameters for Connecting to the Database in Different Scenarios
- JDBC API Reference
- java.sql.Connection
- java.sql.CallableStatement
- java.sql.DatabaseMetaData
- java.sql.Driver
- java.sql.PreparedStatement
- java.sql.ResultSet
- java.sql.ResultSetMetaData
- java.sql.Statement
- javax.sql.ConnectionPoolDataSource
- javax.sql.DataSource
- javax.sql.PooledConnection
- javax.naming.Context
- javax.naming.spi.InitialContextFactory
- CopyManager
- JDBC-based Common Parameter Reference
- Development Based on ODBC
- Development Based on libpq
- Dependent Header Files of libpq
- Development Process
- Example
- Link Parameters
- libpq API Reference
- Database Connection Control Functions
- Database Statement Execution Functions
- Functions for Asynchronous Command Processing
- Functions for Canceling Queries in Progress
- Psycopg-Based Development
- Commissioning
- Stored Procedure
- User Defined Functions
- PL/pgSQL-SQL Procedural Language
- Scheduled Jobs
- Autonomous Transaction
- Logical Replication
- Extension
- Materialized View
- Materialized View Overview
- Full Materialized View
- Incremental Materialized View
- Partition Management
- Partition Pruning
- Recommendations For Choosing A Partitioning Strategy
- Application Development Guide
- Performance Tuning Guide
- System Optimization
- SQL Optimization
- WDR Snapshot
- Using the Vectorized Executor for Tuning
- TPC-C Performance Tunning Guide
- Reference Guide
- System Catalogs and System Views
- Overview of System Catalogs and System Views
- System Catalogs
- GS_ASP
- GS_AUDITING_POLICY
- GS_AUDITING_POLICY_ACCESS
- GS_AUDITING_POLICY_FILTERS
- GS_AUDITING_POLICY_PRIVILEGES
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_DB_PRIVILEGE
- GS_ENCRYPTED_COLUMNS
- GS_ENCRYPTED_PROC
- GS_GLOBAL_CHAIN
- GS_GLOBAL_CONFIG
- GS_MASKING_POLICY
- GS_MASKING_POLICY_ACTIONS
- GS_MASKING_POLICY_FILTERS
- GS_MATVIEW
- GS_MATVIEW_DEPENDENCY
- GS_MODEL_WAREHOUSE
- GS_OPT_MODEL
- GS_PACKAGE
- GS_POLICY_LABEL
- GS_RECYCLEBIN
- GS_TXN_SNAPSHOT
- GS_UID
- GS_WLM_EC_OPERATOR_INFO
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_SESSION_QUERY_INFO_ALL
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_AUTHID
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_HASHBUCKET
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_PUBLICATION
- PG_PUBLICATION_REL
- PG_RANGE
- PG_REPLICATION_ORIGIN
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SET
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SUBSCRIPTION
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PGXC_SLICE
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- System Views
- DV_SESSION_LONGOPS
- DV_SESSIONS
- GET_GLOBAL_PREPARED_XACTS(Discarded)
- GS_AUDITING
- GS_AUDITING_ACCESS
- GS_AUDITING_PRIVILEGE
- GS_ASYNC_SUBMIT_SESSIONS_STATUS
- GS_CLUSTER_RESOURCE_INFO
- GS_COMPRESSION
- GS_DB_PRIVILEGES
- GS_FILE_STAT
- GS_GSC_MEMORY_DETAIL
- GS_INSTANCE_TIME
- GS_LABELS
- GS_LSC_MEMORY_DETAIL
- GS_MASKING
- GS_MATVIEWS
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY
- GS_SESSION_MEMORY_CONTEXT
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_MEMORY_STATISTICS
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_SQL_COUNT
- GS_STAT_SESSION_CU
- GS_THREAD_MEMORY_CONTEXT
- GS_TOTAL_MEMORY_DETAIL
- GS_WLM_CGROUP_INFO
- GS_WLM_EC_OPERATOR_STATISTICS
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_INFO_ALL
- GS_WLM_SESSION_STATISTICS
- GS_WLM_USER_INFO
- GS_WRITE_TERM_LOG
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_COMM_DELAY
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_STATUS
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_ATTACHED_PIDS
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_INDEXES
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_PUBLICATION_TABLES
- PG_REPLICATION_ORIGIN_STATUS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SESSION_IOSTAT
- PG_SESSION_WLMSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_STAT_ACTIVITY
- PG_STAT_ACTIVITY_NG
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_REPLICATION
- PG_STAT_SUBSCRIPTION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_STATS
- PG_TABLES
- PG_TDE_INFO
- PG_THREAD_WAIT_STATUS
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_USER_RESOURCE_INFO
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_USER
- PG_USER_MAPPINGS
- PG_VARIABLE_INFO
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_PREPARED_XACTS
- PLAN_TABLE
- Functions and Operators
- Logical Operators
- Comparison Operators
- Character Processing Functions and Operators
- Binary String Functions and Operators
- Bit String Functions and Operators
- Mode Matching Operators
- Mathematical Functions and Operators
- Date and Time Processing Functions and Operators
- Type Conversion Functions
- Geometric Functions and Operators
- Network Address Functions and Operators
- Text Search Functions and Operators
- JSON/JSONB Functions and Operators
- HLL Functions and Operators
- SEQUENCE Functions
- Array Functions and Operators
- Range Functions and Operators
- Aggregate Functions
- Window Functions(Analysis Functions)
- Security Functions
- Ledger Database Functions
- Encrypted Equality Functions
- Set Returning Functions
- Conditional Expression Functions
- System Information Functions
- System Administration Functions
- Configuration Settings Functions
- Universal File Access Functions
- Server Signal Functions
- Backup and Restoration Control Functions
- Snapshot Synchronization Functions
- Database Object Functions
- Advisory Lock Functions
- Logical Replication Functions
- Segment-Page Storage Functions
- Other Functions
- Undo System Functions
- Row-Store Compression System Functions
- Statistics Information Functions
- Trigger Functions
- Hash Function
- Prompt Message Function
- Global Temporary Table Functions
- Fault Injection System Function
- AI Feature Functions
- Dynamic Data Masking Functions
- Other System Functions
- Internal Functions
- Global SysCache Feature Functions
- Data Damage Detection and Repair Functions
- Obsolete Functions
- Supported Data Types
- Numeric Types
- Monetary Types
- Boolean Types
- Enumerated Types
- Character Types
- Binary Types
- Date/Time Types
- Geometric
- Network Address Types
- Bit String Types
- Text Search Types
- UUID
- JSON/JSONB Types
- HLL
- Array Types
- Range
- OID Types
- Pseudo-Types
- Data Types Supported by Column-store Tables
- XML Types
- Data Type Used by the Ledger Database
- SET Type
- SQL Syntax
- ABORT
- ALTER AGGREGATE
- ALTER AUDIT POLICY
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER EXTENSION
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GLOBAL CONFIGURATION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MASKING POLICY
- ALTER MATERIALIZED VIEW
- ALTER PACKAGE
- ALTER PROCEDURE
- ALTER PUBLICATION
- ALTER RESOURCE LABEL
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SUBSCRIPTION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLE SUBPARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- CONNECT BY
- COPY
- CREATE AGGREGATE
- CREATE AUDIT POLICY
- CREATE CAST
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE EXTENSION
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INCREMENTAL MATERIALIZED VIEW
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MASKING POLICY
- CREATE MATERIALIZED VIEW
- CREATE MODEL
- CREATE OPERATOR
- CREATE PACKAGE
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE RESOURCE LABEL
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE ROW LEVEL SECURITY POLICY
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SUBSCRIPTION
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLE SUBPARTITION
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CREATE WEAK PASSWORD DICTIONARY
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DO
- DROP AGGREGATE
- DROP AUDIT POLICY
- DROP CAST
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP EXTENSION
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GLOBAL CONFIGURATION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MASKING POLICY
- DROP MATERIALIZED VIEW
- DROP MODEL
- DROP OPERATOR
- DROP OWNED
- DROP PACKAGE
- DROP PROCEDURE
- DROP PUBLICATION
- DROP RESOURCE LABEL
- DROP RESOURCE POOL
- DROP ROLE
- DROP ROW LEVEL SECURITY POLICY
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SUBSCRIPTION
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- DROP WEAK PASSWORD DICTIONARY
- EXECUTE
- EXECUTE DIRECT
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MERGE INTO
- MOVE
- PREDICT BY
- PREPARE
- PREPARE TRANSACTION
- PURGE
- REASSIGN OWNED
- REFRESH INCREMENTAL MATERIALIZED VIEW
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHUTDOWN
- SNAPSHOT
- START TRANSACTION
- TIMECAPSULE TABLE
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- SHRINK
- SQL Reference
- MogDB SQL
- Keywords
- Constant and Macro
- Expressions
- Type Conversion
- Full Text Search
- Introduction
- Tables and Indexes
- Controlling Text Search
- Additional Features
- Parser
- Dictionaries
- Configuration Examples
- Testing and Debugging Text Search
- Limitations
- System Operation
- Controlling Transactions
- DDL Syntax Overview
- DML Syntax Overview
- DCL Syntax Overview
- Appendix
- GUC Parameters
- GUC Parameter Usage
- GUC Parameter List
- File Location
- Connection and Authentication
- Resource Consumption
- Write Ahead Log
- HA Replication
- Memory Table
- Query Planning
- Error Reporting and Logging
- Alarm Detection
- Statistics During the Database Running
- Load Management
- Automatic Vacuuming
- Default Settings of Client Connection
- Lock Management
- Version and Platform Compatibility
- Faut Tolerance
- Connection Pool Parameters
- MogDB Transaction
- Replication Parameters of Two Database Instances
- Developer Options
- Auditing
- CM Parameters
- Upgrade Parameters
- Miscellaneous Parameters
- Wait Events
- Query
- System Performance Snapshot
- Security Configuration
- Global Temporary Table
- HyperLogLog
- Scheduled Task
- Thread Pool
- User-defined Functions
- Backup and Restoration
- Undo
- DCF Parameters Settings
- Flashback
- Rollback Parameters
- Reserved Parameters
- AI Features
- Global SysCache Parameters
- Parameters Related to Efficient Data Compression Algorithms
- Appendix
- Schema
- Overview
- Information Schema
- DBE_PERF
- Overview
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- LOCAL_ACTIVE_SESSION
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- GLOBAL_SINGLE_FLUSH_DW_STATUS
- GLOBAL_CANDIDATE_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- RTO
- DBE_PLDEBUGGER Schema
- Overview
- DBE_PLDEBUGGER.turn_on
- DBE_PLDEBUGGER.turn_off
- DBE_PLDEBUGGER.local_debug_server_info
- DBE_PLDEBUGGER.attach
- DBE_PLDEBUGGER.info_locals
- DBE_PLDEBUGGER.next
- DBE_PLDEBUGGER.continue
- DBE_PLDEBUGGER.abort
- DBE_PLDEBUGGER.print_var
- DBE_PLDEBUGGER.info_code
- DBE_PLDEBUGGER.step
- DBE_PLDEBUGGER.add_breakpoint
- DBE_PLDEBUGGER.delete_breakpoint
- DBE_PLDEBUGGER.info_breakpoints
- DBE_PLDEBUGGER.backtrace
- DBE_PLDEBUGGER.disable_breakpoint
- DBE_PLDEBUGGER.enable_breakpoint
- DBE_PLDEBUGGER.finish
- DBE_PLDEBUGGER.set_var
- DB4AI Schema
- DBE_PLDEVELOPER
- Tool Reference
- Tool Overview
- Client Tool
- Server Tools
- Tools Used in the Internal System
- Unified Database Management Tool
- FAQ
- Functions of MogDB Executable Scripts
- System Catalogs and Views Supported by gs_collector
- Error Code Reference
- Description of SQL Error Codes
- Third-Party Library Error Codes
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07480
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53799
- Error Log Reference
- System Catalogs and System Views
- Common Faults and Identification
- Common Fault Locating Methods
- Common Fault Locating Cases
- Core Fault Locating
- Permission/Session/Data Type Fault Location
- Service/High Availability/Concurrency Fault Location
- Standby Node in the Need Repair (WAL) State
- Service Startup Failure
- Primary Node Is Hung in Demoting During a Switchover
- "too many clients already" Is Reported or Threads Failed To Be Created in High Concurrency Scenarios
- Performance Deterioration Caused by Dirty Page Flushing Efficiency During TPCC High Concurrentcy Long Term Stable Running
- Table/Partition Table Fault Location
- File System/Disk/Memory Fault Location
- After You Run the du Command to Query Data File Size In the XFS File System, the Query Result Is Greater than the Actual File Size
- File Is Damaged in the XFS File System
- Insufficient Memory
- "Error:No space left on device" Is Displayed
- When the TPC-C is running and a disk to be injected is full, the TPC-C stops responding
- Disk Space Usage Reaches the Threshold and the Database Becomes Read-only
- SQL Fault Location
- Index Fault Location
- CM Two-Node Fault Location
- Source Code Parsing
- FAQs
- Glossary
- Communication Matrix
- Mogeaver
Manual Rectification of the Brain Split Fault in a Database Cluster
Symptom
In the brain split scenario of a database cluster, a primary instance is stopped to be in the manually stopped status. Make sure that there is only one primary instance running normally. You can judge whether there is a brain split fault using the following two methods.
-
Error log
The log of the cm_server primary instance includes split brain failure in db service, as shown in the following.
CM_AGENT ERROR: [Primary], line 1529: split brain failure in db service, more dynamic primary and their term(7504) are the most(7504). Due to auto crash recovery is disabled, no need send restart msg to instance(6002) that had been restarted, waiting for manual intervention.Or
CM_AGENT ERROR: line 570: split brain failure in db service, instance 6002 local term(7403) is not max term(7504). Due to auto crash recovery is disabled, will not restart current instance, waiting for manual intervention. -
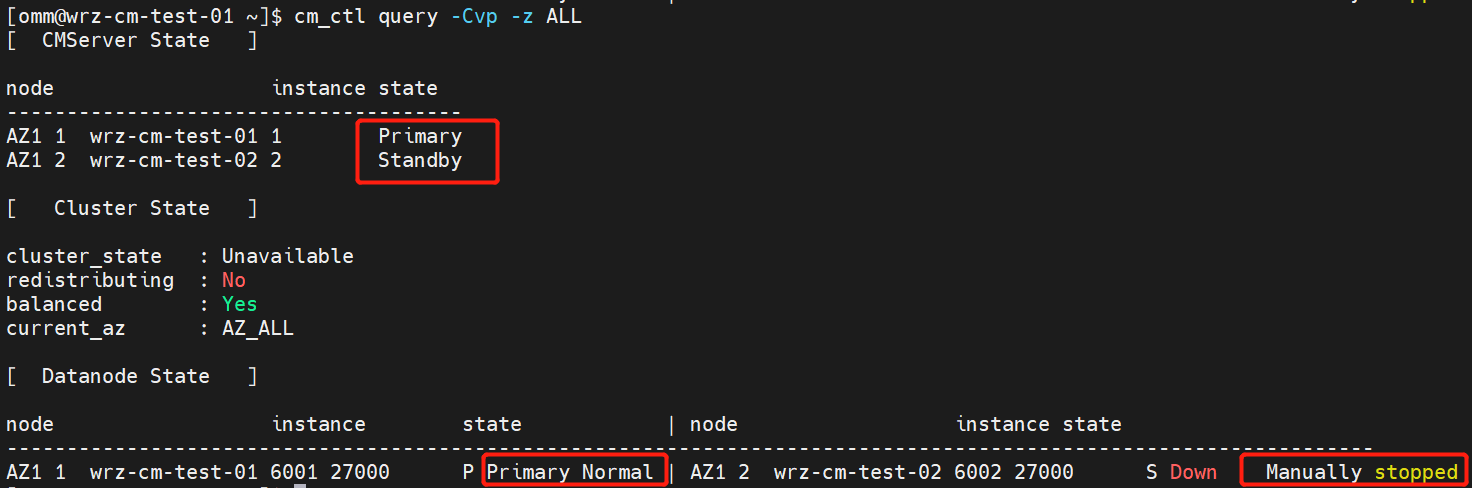
Run the
cm_ctl query -Cvp -z ALLcommand to query the cluster status, as shown in the following figure.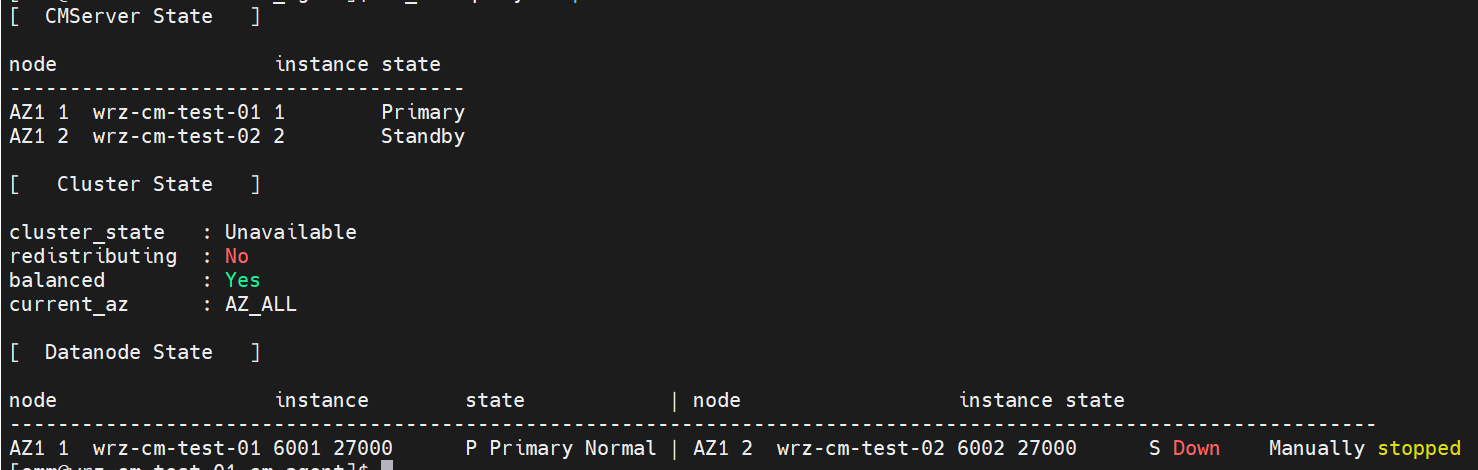
Note: In extreme scenarios, two database instances will be stopped. In this case, start the instance whose ID is small, such as the node 6001 so that it can continuously provide services. The start command is as follows.
cm_ctl start -n <nodeid> -D <datapath>
Cause Analysis
If a network partitioning fault occurs, the failover process may be triggered due to the following reasons to meet the requirement that the instance that owning more votes can continuously provide services.
- cms primary cannot perceive the status of the primary instance in the database cluster.
- The standby instance cannot communicate with the primary instance, such as stream replication error.
- The connectivity between the standby instance and the virtual IP address (configured) is abnormal.
Once the network partitioning fault is rectified, brain split may occur. Additionally, because the automatic fault rectification function cms_enable_db_crash_recovery of the database cluster is disabled, the dual-primary decision will not be made but a primary instance is stopped to ensure that there is one primary instance available and a DBA then manually deal with the issue to ensure data consistency of the database cluster.
Procedure
Tool Download
First, access the Download MogDB: MogDB Downloads page of the MogDB official website, switch to the Package Download tab, choose a version, OS, and CPU, and then choose a package in the ToolKits- \<version>-\<platform-cpuarch>.tar.gz format, as shown in the following figure.
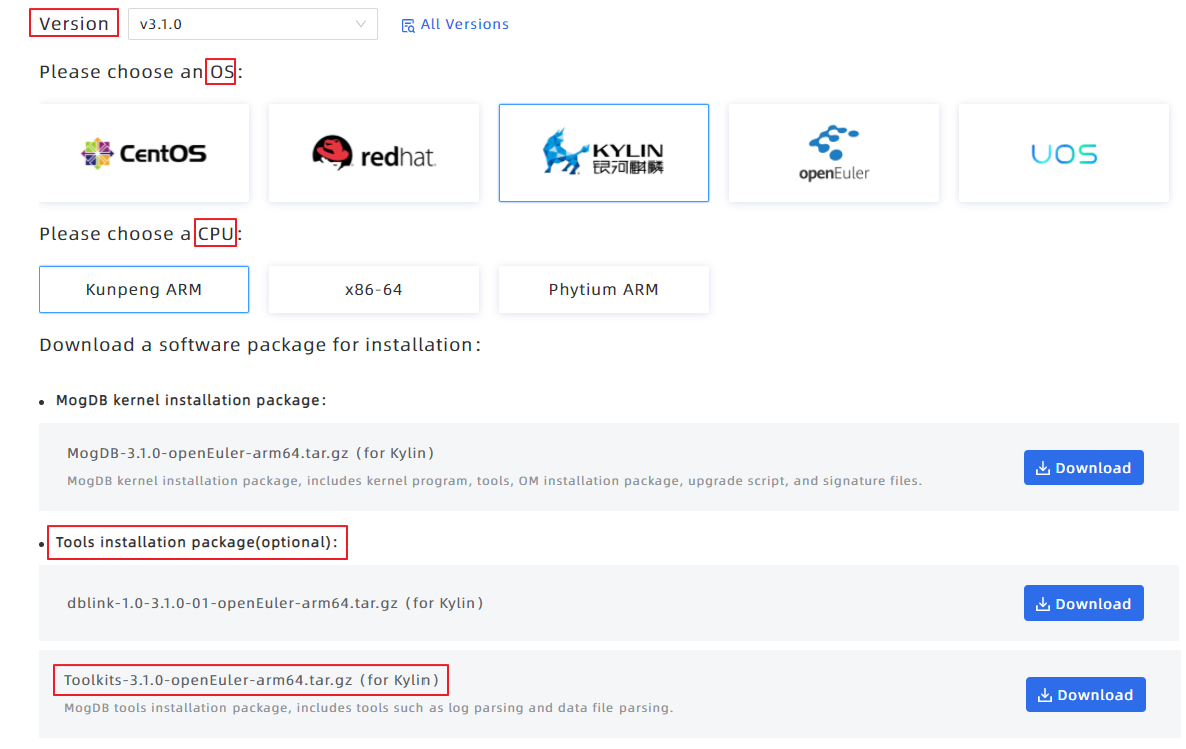
Put the software package in the bin directory of MogDB and decompress it. The mog_xlogdump tool is used for data verification. The decompression result is as follows.

The tool depends on the following parameters.
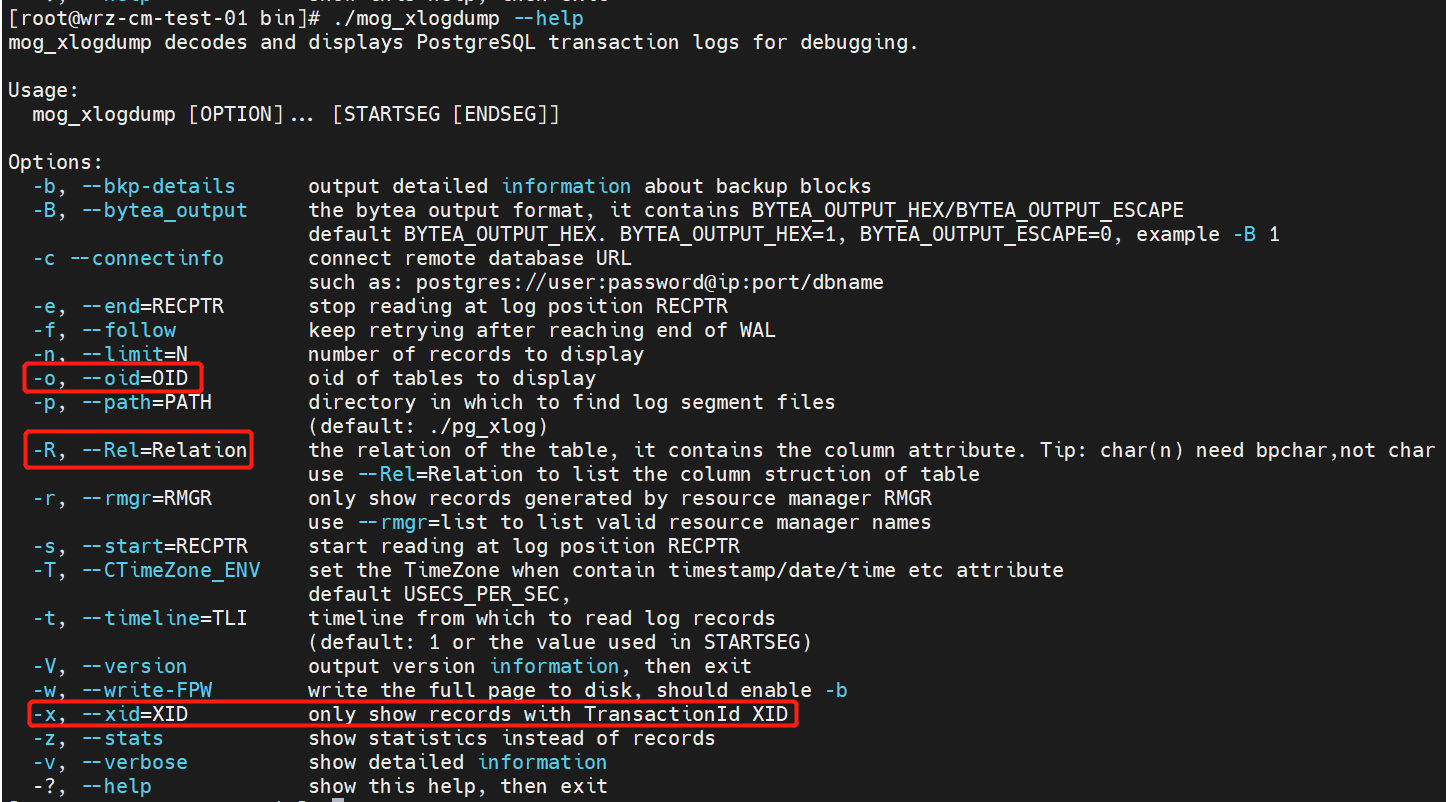
As shown in the figure, mog_xlogdump depends on the transaction ID (-x), OID (-o) of a data table, and the xlog file (-p).
Tool Usage
The brain split fault will cause that the logs of the two database instances differ from a time point. If it lasts a long time, the difference may cause that tens of thousands of data records in single tables or multiple tables are inconsistent (in online environment, even if the difference occurs, it lasts short time and can be controlled). In this case, the DBA needs to confirm the data difference range using the mog_xlogdump tool to facilitate data merging.
Experimental Data Table
The experimental data table is test_example_01.
(1) Create a table on the primary instance and insert five data records.
create table test_example_01(id integer primary key, user_name varchar(10), register_time timestamp);
insert into test_example_01 values(1, 'zhangsan', '2022-09-22 10:57:10');
insert into test_example_01 values(2, 'lisi', '2022-09-22 10:58:10');
insert into test_example_01 values(3, 'wangwu', '2022-09-22 17:03:10');
insert into test_example_01 values(4, 'mazi', '2022-09-22 17:05:10');
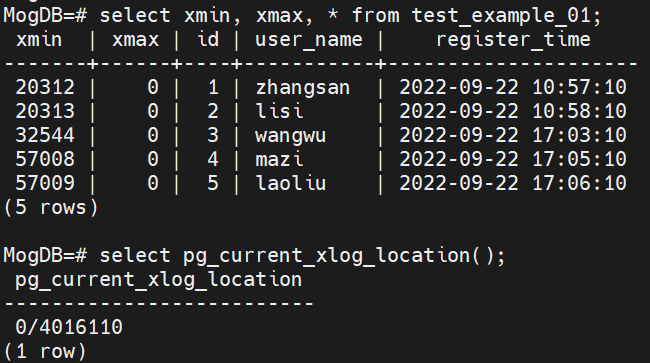
insert into test_example_01 values(5, 'laoliu', '2022-09-22 17:09:10');(2) Query the table information before the network partitioning fault occurs.
\d+ test_example_01; //Query the table structure. 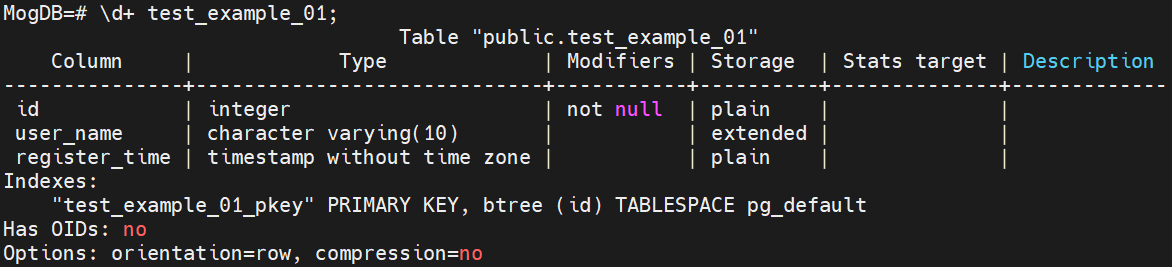
select pg_relation_filenode('test_example_01'); // Query the filenode, that is the OID.
select oid from pg_class where relname='test_example_01'; // Query the OID of the table. 
select xmin, xmax, * from test_example_01; // Query the transaction ID of the table, that is, xmin.
select pg_current_xlog_location(); // Query the WAL log file of the primary instance, such as 000000010000000000000004.-
wrz-cm-test-01 node
Confirm the Data Change Range Based on the Start and End LSN
For tables where data is inconsistent or not is unclear, the mog_xlogdump tool can be used for finding inconsistent data based on the specified start and end LSN, that is, -s and -e. You can run either of the following commands.
mog_xlogdump -c Database connection -s Start lsn -e End lsn wal log file of the primary instance
mog_xlogdump -c Database connection -p xlog directory -s Start lsn -e End lsnNote:
- The database connection string rule is
postgres://<db_user>:<db_pwd>@<host_ip>:\<port>/<db_name>. You do not need to specify it in the local. - Because the OID is not specified, the data obtained using this method contains all table data. It is hard to merge data later.
Confirm the Data Change Range Based on Special Tables (Recommended)
For tables where data is inconsistent or not is unclear, the mog_xlogdump tool can be used for parsing data of the table with specified OID based on the parameters -o and -R, and start and end LSN, that is, -s and -e. You can run either of the following commands.
mog_xlogdump -c Database connection -o OID of a table -R Column type of a table -s Start lsn -e End lsn wal log file of the primary instance
mog_xlogdump -c Database connection -p xlog directory -o OID of a table -R Column type of a table -s Start lsn -e End lsnNote: The database connection string rule is postgres://<db_user>:<db_pwd>@<host_ip>:\<port>/<db_name>. You do not need to specify it in the local.
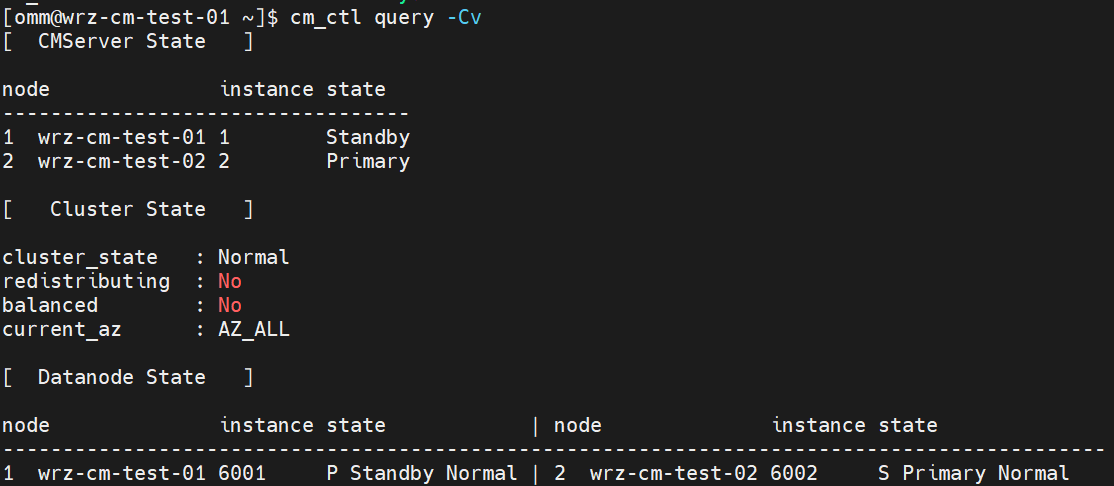
(1) Query the cluster status to make sure that the cluster is running normally.
(2) Use a firewall to simulate network isolation between the primary and standby nodes
Run the following command on any node of the cluster and isolate its network from the other node.
iptables -I OUTPUT -d 192.168.122.232 -j DROP; iptables -I INPUT -s 192.168.122.232 -j DROP(3) Query the cluster status to make sure that the CMS and database instance role in each partition is primary.
-
wrz-cm-test-01 node
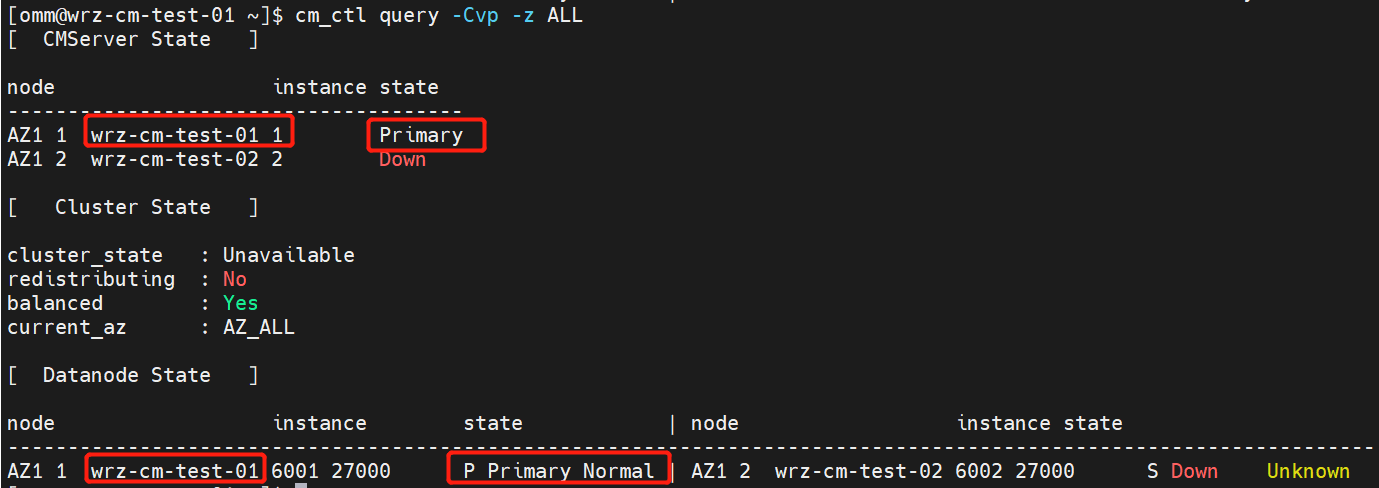
-
wrz-cm-test-02 node
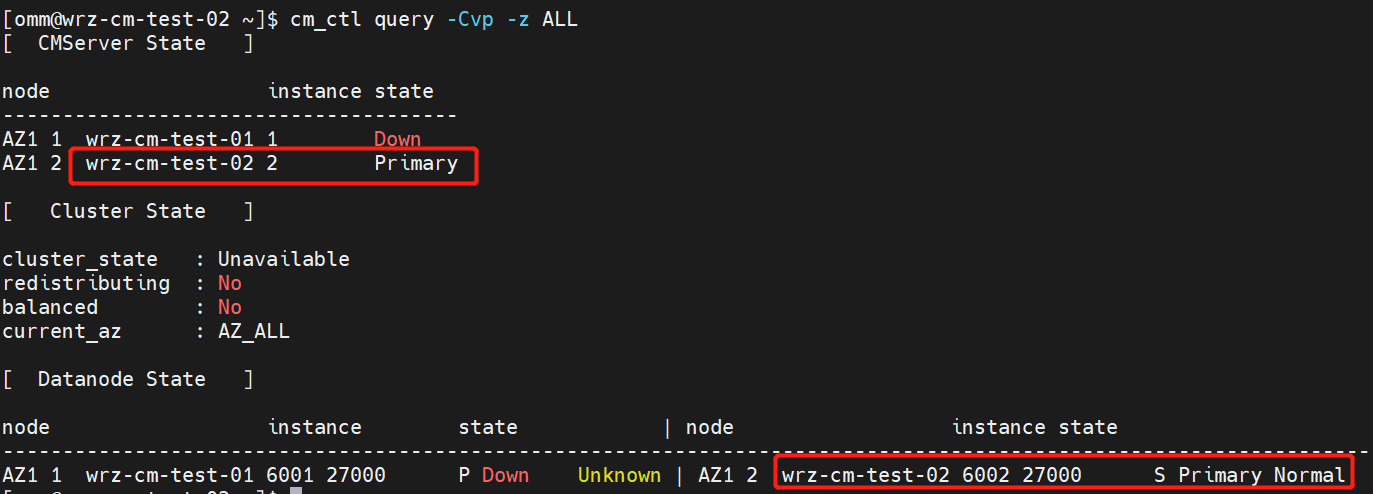
Perform the Write, Update, and Delete Operations on the Primary Instances in Different Partitions
(1) Perform the write operation on the wrz-cm-test-01 node.
insert into test_example_01 values(6, 'xiaoming', '2022-09-22 17:09:10'); // Repeated IDs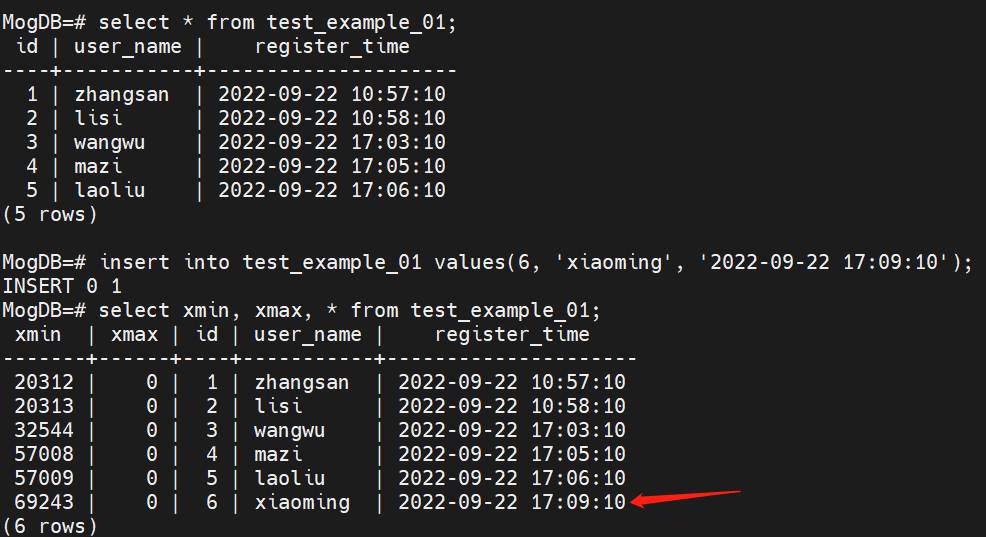
(2) Perform the write operation on the wrz-cm-test-02 node.
insert into test_example_01 values(6, 'xiaoming', '2022-09-22 17:10:10'); // Repeated IDs
insert into test_example_01 values(7, 'huluwa', '2022-09-22 17:12:10');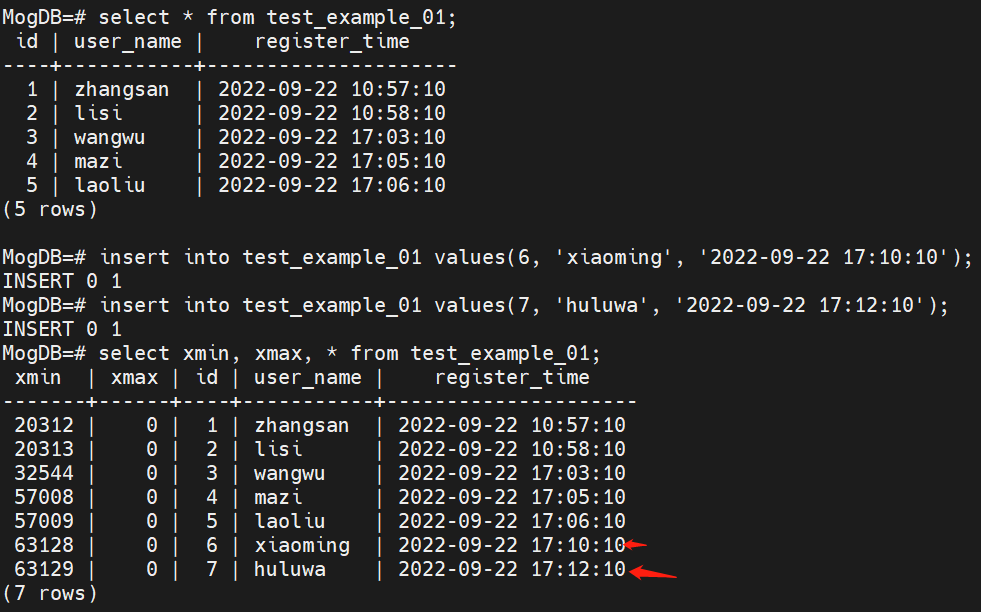
Rectify the Network Partitioning Fault
(1) Clear the firewall.
Run the following command on the node in the second procedure in the network partitioning fault simulation part.
iptables -I OUTPUT -d 192.168.122.232 -j ACCEPT; iptables -I INPUT -s 192.168.122.232 -j ACCEPT(2) Query the cluster status to make sure that it is running normally.
The cluster status is consistent with that in the Symptom part, that is, the cluster is in the manually stopped status.
Data Recovery and Merging
This procedure depends on logs. Once log data is lost, data recovery will fail. Assume that there is only one table (test_example_01) whose data is changed after network partitioning.
(1) Confirm the LSN information before the network partitioning fault occurs and when the brain split occurs.
-
Judge the time point at which the networking partitioning fault occurs.
Based on the original cluster status of the node in simulating the network partitioning fault, the CMS and the database instance role on the wrz-cm-test-01 node will be changed as the primary instance after the network partitioning fault occurs. Therefore, the time point when the CMS is changed to a primary instance can be found in the cm_server log of the wrz-cm-test-01 node. With the time point, the LSN information corresponding to the last data synchronization of the primary and standby instances when the cluster is running normally can be obtained. (-s indicates the start time for mog_xlogdump to parse the log).
The log for the CMS to be switched as the primary instance is as follows.
/cm_server-2022-09-23_104436-current.log:2022-09-23 15:16:23.005 tid=1245295 LOG: [DccNotifyStatus] g_dbRole is 1, roleType is 1.The LSN information reported from the CMA node before the CMS is switched to be a primary node is as follows.
2022-09-23 14:59:27.495 tid=1245411 CM_AGENT LOG: [InstanceIsUnheal], current report instance is 6001, node 1, instId[6001: 6002], node[1: 2], staticRole[2=Standby: 1=Primary], dynamicRole[2=Standby: 5=Down], term[703: 604], lsn[0/4016230: 0/4007840], dbState[2: 0], buildReason[2=Disconnected: 7=Unknown], doubleRestarting[0: 0], disconn_mode[3=prohibit_connection: 1=polling_connection], disconn[:0, :0], local[192.168.122.231:27001, 192.168.122.232:27001], redoFinished[1: 1], arbiTime[104: 100], syncList[cur: (sync list is empty), exp: (sync list is empty), vote: (dynamic status is empty)], groupTerm[604], sync_standby_mode[0: 0: 0]. -
Judge the time point at which brain split occurs in the cluster.
Based on the brain split fault rectification mechanism, the LSN corresponding to the time point at which the brain split occurs can be replaced with the xlog position of the manually stopped database instance. (-e indicates the end time for mog_xlogdump to parse the log.)
Under network isolation, start the manually stopped database instance, log in to the instance using gsql, and run the following command to obtain the xlog position.
select pg_current_xlog_location();
(2) Use a firewall to isolate the node where the database instance is manually stopped and start the database instance on the node.
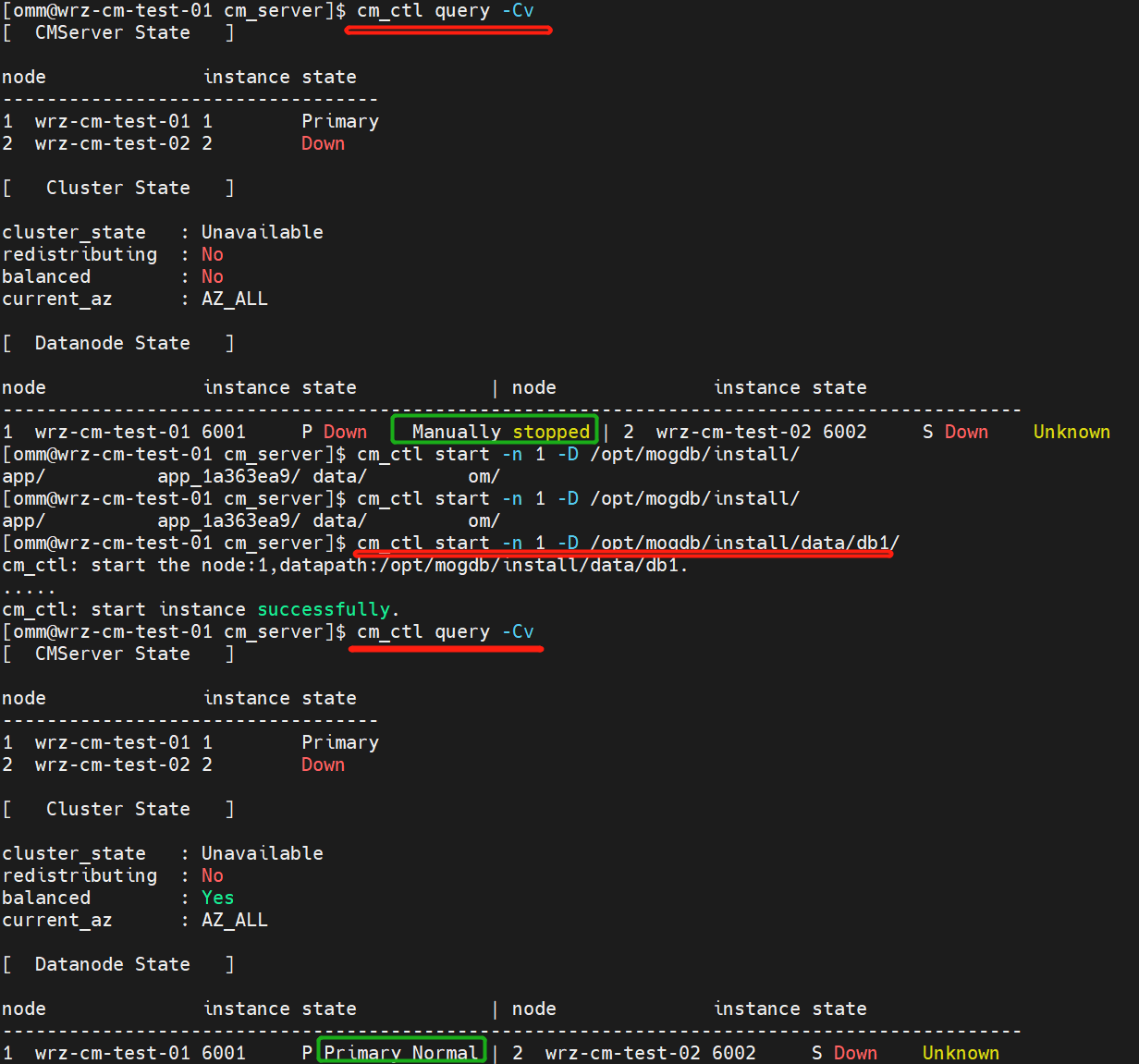
Obtain the data of the test_example_01 table and the LSN information when the brain split fault occurs.
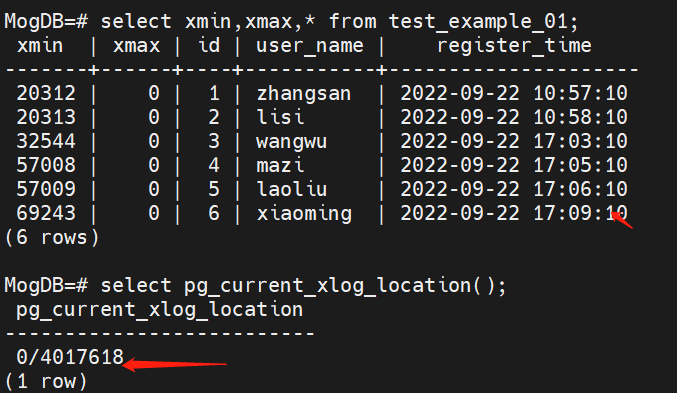
(3) Use mog_xlogdump to confirm the data change range, and export the data.
Data change on the wrz-cm-test-01 node:

Data change on the wrz-cm-test-02 node:

Generate the data to be merged into the primary instance of the current database cluster.
insert into test_example_01 values(6, 'xiaoming', '2022-09-22 17:10:10'); // IDs conflict. Choose the ID of the latest time.
insert into test_example_01 values(7, 'huluwa', '2022-09-22 17:12:10');After confirmation, stop the current database instance.
(4) Import the changed data into the primary instance of the database cluster.
Use gsql to log in to the primary instance and perform the above insert statement.
Query the database record after data is merged.
(5) Add the manually stopped database instance to the database cluster.
Based on the second step, make sure that the database instance on the node is in the stopped status, clear the firewall to cancel network isolation, and start the database instance on the node by running the cm_ctl start -n nodeid -D datapath command.
The instance will be added to the database cluster as a standby instance.
(6) Query the cluster status to ensure that any device is normal.