- 关于MogDB
- 快速入门
- 安装指南
- 管理指南
- 日常运维
- 主备管理
- 高可用管理
- MOT内存表管理
- 列存表管理
- 备份与恢复
- 数据导出导入
- 升级指南
- 常见故障处理指南
- 常见故障定位手段
- 常见故障定位案例
- core问题定位
- TPCC运行时,注入磁盘满故障,TPCC卡住的问题
- 备机处于need repair(WAL)状态问题
- 内存不足问题
- 服务启动失败
- 出现“Error:No space left on device”提示
- 在XFS文件系统中,使用du命令查询数据文件大小大于文件实际大小
- 在XFS文件系统中,出现文件损坏
- switchover操作时,主机降备卡住
- 磁盘空间达到阈值,数据库只读
- 分析查询语句长时间运行的问题
- 分析查询语句运行状态
- 强制结束指定的问题会话
- 分析查询语句是否被阻塞
- 分析查询效率异常降低的问题
- 执行 SQL 语句时,提示 Lock wait timeout
- VACUUM FULL一张表后,表文件大小无变化
- 执行修改表分区操作时报错
- 不同用户查询同表显示数据不同
- 修改索引时只调用索引名提示索引不存在
- 重建索引失败
- 业务运行时整数转换错
- 高并发报错”too many clients already”或无法创建线程
- btree 索引故障情况下应对策略
- 安全指南
- 性能优化指南
- 开发者指南
- 参考指南
- 系统表及系统视图
- 系统表和系统视图概述
- 系统表
- GS_CLIENT_GLOBAL_KEYS
- GS_CLIENT_GLOBAL_KEYS_ARGS
- GS_COLUMN_KEYS
- GS_COLUMN_KEYS_ARGS
- GS_ENCRYPTED_COLUMNS
- GS_OPT_MODEL
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_PLAN_ENCODING_TABLE
- GS_WLM_PLAN_OPERATOR_INFO
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_APP_WORKLOADGROUP_MAPPING
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTHID
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_DIRECTORY
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_INDEX
- PG_INHERITS
- PG_JOB
- PG_JOB_PROC
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_RANGE
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_RLSPOLICY
- PG_SECLABEL
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_GROUP
- PLAN_TABLE_DATA
- STATEMENT_HISTORY
- 系统视图
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY_STATISTICS
- GS_SQL_COUNT
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_PLAN_OPERATOR_HISTORY
- GS_WLM_REBUILD_USER_RESOURCE_POOL
- GS_WLM_RESOURCE_POOL
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_INFO_ALL
- GS_WLM_USER_INFO
- GS_WLM_SESSION_STATISTICS
- GS_STAT_SESSION_CU
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_GTT_RELSTATS
- PG_GTT_STATS
- PG_GTT_ATTACHED_PIDS
- PG_INDEXES
- PG_LOCKS
- PG_MATVIEWS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_REPLICATION_SLOTS
- PG_RLSPOLICIES
- PG_ROLES
- PG_RULES
- PG_SECLABELS
- PG_SESSION_WLMSTAT
- PG_SESSION_IOSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_STATS
- PG_STAT_ACTIVITY
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_REPLICATION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_THREAD_WAIT_STATUS
- PG_TABLES
- PG_TDE_INFO
- PG_TIMEZONE_NAMES
- PG_TOTAL_USER_RESOURCE_INFO
- PG_USER
- PG_USER_MAPPINGS
- PG_VIEWS
- PG_WLM_STATISTICS
- PLAN_TABLE
- GS_FILE_STAT
- GS_OS_RUN_INFO
- GS_REDO_STAT
- GS_SESSION_MEMORY
- GS_SESSION_MEMORY_DETAIL
- GS_SESSION_STAT
- GS_SESSION_TIME
- GS_THREAD_MEMORY_DETAIL
- GS_TOTAL_MEMORY_DETAIL
- PG_TIMEZONE_ABBREVS
- PG_TOTAL_USER_RESOURCE_INFO_OID
- PG_VARIABLE_INFO
- GS_INSTANCE_TIME
- 系统函数
- 支持的数据类型
- SQL 语法
- ABORT
- ALTER DATABASE
- ALTER DATA SOURCE
- ALTER DEFAULT PRIVILEGES
- ALTER DIRECTORY
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GROUP
- ALTER INDEX
- ALTER LARGE OBJECT
- ALTER MATERIALIZED VIEW
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER SYSTEM SET
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE | ANALYSE
- BEGIN
- CALL
- CHECKPOINT
- CLOSE
- CLUSTER
- COMMENT
- COMMIT | END
- COMMIT PREPARED
- COPY
- CREATE CLIENT MASTER KEY
- CREATE COLUMN ENCRYPTION KEY
- CREATE DATABASE
- CREATE DATA SOURCE
- CREATE DIRECTORY
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INDEX
- CREATE MATERIALIZED VIEW
- CREATE ROW LEVEL SECURITY POLICY
- CREATE PROCEDURE
- CREATE ROLE
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- CURSOR
- DEALLOCATE
- DECLARE
- DELETE
- DO
- DROP CLIENT MASTER KEY
- DROP COLUMN ENCRYPTION KEY
- DROP DATABASE
- DROP DATA SOURCE
- DROP DIRECTORY
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GROUP
- DROP INDEX
- DROP MATERIALIZED VIEW
- DROP OWNED
- DROP ROW LEVEL SECURITY POLICY
- DROP PROCEDURE
- DROP ROLE
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SYNONYM
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- EXECUTE
- EXPLAIN
- EXPLAIN PLAN
- FETCH
- GRANT
- INSERT
- LOCK
- MOVE
- MERGE INTO
- PREPARE
- PREPARE TRANSACTION
- REASSIGN OWNED
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- SHUTDOW
- START TRANSACTION
- TRUNCATE
- UPDATE
- VACUUM
- VALUES
- GUC参数说明
- DBE_PERF
- 概述
- OS
- Instance
- Memory
- File
- Object
- STAT_USER_TABLES
- SUMMARY_STAT_USER_TABLES
- GLOBAL_STAT_USER_TABLES
- STAT_USER_INDEXES
- SUMMARY_STAT_USER_INDEXES
- GLOBAL_STAT_USER_INDEXES
- STAT_SYS_TABLES
- SUMMARY_STAT_SYS_TABLES
- GLOBAL_STAT_SYS_TABLES
- STAT_SYS_INDEXES
- SUMMARY_STAT_SYS_INDEXES
- GLOBAL_STAT_SYS_INDEXES
- STAT_ALL_TABLES
- SUMMARY_STAT_ALL_TABLES
- GLOBAL_STAT_ALL_TABLES
- STAT_ALL_INDEXES
- SUMMARY_STAT_ALL_INDEXES
- GLOBAL_STAT_ALL_INDEXES
- STAT_DATABASE
- SUMMARY_STAT_DATABASE
- GLOBAL_STAT_DATABASE
- STAT_DATABASE_CONFLICTS
- SUMMARY_STAT_DATABASE_CONFLICTS
- GLOBAL_STAT_DATABASE_CONFLICTS
- STAT_XACT_ALL_TABLES
- SUMMARY_STAT_XACT_ALL_TABLES
- GLOBAL_STAT_XACT_ALL_TABLES
- STAT_XACT_SYS_TABLES
- SUMMARY_STAT_XACT_SYS_TABLES
- GLOBAL_STAT_XACT_SYS_TABLES
- STAT_XACT_USER_TABLES
- SUMMARY_STAT_XACT_USER_TABLES
- GLOBAL_STAT_XACT_USER_TABLES
- STAT_XACT_USER_FUNCTIONS
- SUMMARY_STAT_XACT_USER_FUNCTIONS
- GLOBAL_STAT_XACT_USER_FUNCTIONS
- STAT_BAD_BLOCK
- SUMMARY_STAT_BAD_BLOCK
- GLOBAL_STAT_BAD_BLOCK
- STAT_USER_FUNCTIONS
- SUMMARY_STAT_USER_FUNCTIONS
- GLOBAL_STAT_USER_FUNCTIONS
- Workload
- Session/Thread
- SESSION_STAT
- GLOBAL_SESSION_STAT
- SESSION_TIME
- GLOBAL_SESSION_TIME
- SESSION_MEMORY
- GLOBAL_SESSION_MEMORY
- SESSION_MEMORY_DETAIL
- GLOBAL_SESSION_MEMORY_DETAIL
- SESSION_STAT_ACTIVITY
- GLOBAL_SESSION_STAT_ACTIVITY
- THREAD_WAIT_STATUS
- GLOBAL_THREAD_WAIT_STATUS
- LOCAL_THREADPOOL_STATUS
- GLOBAL_THREADPOOL_STATUS
- SESSION_CPU_RUNTIME
- SESSION_MEMORY_RUNTIME
- STATEMENT_IOSTAT_COMPLEX_RUNTIME
- Transaction
- Query
- STATEMENT
- SUMMARY_STATEMENT
- STATEMENT_COUNT
- GLOBAL_STATEMENT_COUNT
- SUMMARY_STATEMENT_COUNT
- GLOBAL_STATEMENT_COMPLEX_HISTORY
- GLOBAL_STATEMENT_COMPLEX_HISTORY_TABLE
- GLOBAL_STATEMENT_COMPLEX_RUNTIME
- STATEMENT_RESPONSETIME_PERCENTILE
- STATEMENT_USER_COMPLEX_HISTORY
- STATEMENT_COMPLEX_RUNTIME
- STATEMENT_COMPLEX_HISTORY_TABLE
- STATEMENT_COMPLEX_HISTORY
- STATEMENT_WLMSTAT_COMPLEX_RUNTIME
- STATEMENT_HISTORY
- Cache/IO
- STATIO_USER_TABLES
- SUMMARY_STATIO_USER_TABLES
- GLOBAL_STATIO_USER_TABLES
- STATIO_USER_INDEXES
- SUMMARY_STATIO_USER_INDEXES
- GLOBAL_STATIO_USER_INDEXES
- STATIO_USER_SEQUENCES
- SUMMARY_STATIO_USER_SEQUENCES
- GLOBAL_STATIO_USER_SEQUENCES
- STATIO_SYS_TABLES
- SUMMARY_STATIO_SYS_TABLES
- GLOBAL_STATIO_SYS_TABLES
- STATIO_SYS_INDEXES
- SUMMARY_STATIO_SYS_INDEXES
- GLOBAL_STATIO_SYS_INDEXES
- STATIO_SYS_SEQUENCES
- SUMMARY_STATIO_SYS_SEQUENCES
- GLOBAL_STATIO_SYS_SEQUENCES
- STATIO_ALL_TABLES
- SUMMARY_STATIO_ALL_TABLES
- GLOBAL_STATIO_ALL_TABLES
- STATIO_ALL_INDEXES
- SUMMARY_STATIO_ALL_INDEXES
- GLOBAL_STATIO_ALL_INDEXES
- STATIO_ALL_SEQUENCES
- SUMMARY_STATIO_ALL_SEQUENCES
- GLOBAL_STATIO_ALL_SEQUENCES
- GLOBAL_STAT_DB_CU
- GLOBAL_STAT_SESSION_CU
- Utility
- REPLICATION_STAT
- GLOBAL_REPLICATION_STAT
- REPLICATION_SLOTS
- GLOBAL_REPLICATION_SLOTS
- BGWRITER_STAT
- GLOBAL_BGWRITER_STAT
- GLOBAL_CKPT_STATUS
- GLOBAL_DOUBLE_WRITE_STATUS
- GLOBAL_PAGEWRITER_STATUS
- GLOBAL_RECORD_RESET_TIME
- GLOBAL_REDO_STATUS
- GLOBAL_RECOVERY_STATUS
- CLASS_VITAL_INFO
- USER_LOGIN
- SUMMARY_USER_LOGIN
- GLOBAL_GET_BGWRITER_STATUS
- Lock
- Wait Events
- Configuration
- Operator
- Workload Manager
- Global Plancache
- 附录
- 数据库报错信息
- SQL标准错误码说明
- 第三方库错误码说明
- GAUSS-00001 - GAUSS-00100
- GAUSS-00101 - GAUSS-00200
- GAUSS 00201 - GAUSS 00300
- GAUSS 00301 - GAUSS 00400
- GAUSS 00401 - GAUSS 00500
- GAUSS 00501 - GAUSS 00600
- GAUSS 00601 - GAUSS 00700
- GAUSS 00701 - GAUSS 00800
- GAUSS 00801 - GAUSS 00900
- GAUSS 00901 - GAUSS 01000
- GAUSS 01001 - GAUSS 01100
- GAUSS 01101 - GAUSS 01200
- GAUSS 01201 - GAUSS 01300
- GAUSS 01301 - GAUSS 01400
- GAUSS 01401 - GAUSS 01500
- GAUSS 01501 - GAUSS 01600
- GAUSS 01601 - GAUSS 01700
- GAUSS 01701 - GAUSS 01800
- GAUSS 01801 - GAUSS 01900
- GAUSS 01901 - GAUSS 02000
- GAUSS 02001 - GAUSS 02100
- GAUSS 02101 - GAUSS 02200
- GAUSS 02201 - GAUSS 02300
- GAUSS 02301 - GAUSS 02400
- GAUSS 02401 - GAUSS 02500
- GAUSS 02501 - GAUSS 02600
- GAUSS 02601 - GAUSS 02700
- GAUSS 02701 - GAUSS 02800
- GAUSS 02801 - GAUSS 02900
- GAUSS 02901 - GAUSS 03000
- GAUSS 03001 - GAUSS 03100
- GAUSS 03101 - GAUSS 03200
- GAUSS 03201 - GAUSS 03300
- GAUSS 03301 - GAUSS 03400
- GAUSS 03401 - GAUSS 03500
- GAUSS 03501 - GAUSS 03600
- GAUSS 03601 - GAUSS 03700
- GAUSS 03701 - GAUSS 03800
- GAUSS 03801 - GAUSS 03900
- GAUSS 03901 - GAUSS 04000
- GAUSS 04001 - GAUSS 04100
- GAUSS 04101 - GAUSS 04200
- GAUSS 04201 - GAUSS 04300
- GAUSS 04301 - GAUSS 04400
- GAUSS 04401 - GAUSS 04500
- GAUSS 04501 - GAUSS 04600
- GAUSS 04601 - GAUSS 04700
- GAUSS 04701 - GAUSS 04800
- GAUSS 04801 - GAUSS 04900
- GAUSS 04901 - GAUSS 05000
- GAUSS 05001 - GAUSS 05100
- GAUSS 05101 - GAUSS 05200
- GAUSS 05201 - GAUSS 05300
- GAUSS 05301 - GAUSS 05400
- GAUSS 05401 - GAUSS 05500
- GAUSS 05501 - GAUSS 05600
- GAUSS 05601 - GAUSS 05700
- GAUSS 05701 - GAUSS 05800
- GAUSS 05801 - GAUSS 05900
- GAUSS 05901 - GAUSS 06000
- GAUSS 06001 - GAUSS 06100
- GAUSS 06101 - GAUSS 06200
- GAUSS 06201 - GAUSS 06300
- GAUSS 06301 - GAUSS 06400
- GAUSS 06401 - GAUSS 06500
- GAUSS 06501 - GAUSS 06600
- GAUSS 06601 - GAUSS 06700
- GAUSS 06701 - GAUSS 06800
- GAUSS 06801 - GAUSS 06900
- GAUSS 06901 - GAUSS 07000
- GAUSS 07001 - GAUSS 07100
- GAUSS 07101 - GAUSS 07200
- GAUSS 07201 - GAUSS 07300
- GAUSS 07301 - GAUSS 07400
- GAUSS 07401 - GAUSS 07480
- GAUSS 50000 - GAUSS 50999
- GAUSS 51000 - GAUSS 51999
- GAUSS 52000 - GAUSS 52999
- GAUSS 53000 - GAUSS 53699
- 系统表及系统视图
- 术语表
Query执行流程
简介
SQL引擎从接受SQL语句到执行SQL语句需要经历的步骤如图1和说明1所示。其中,红色字体部分为DBA可以介入实施调优的环节。
图 1 SQL引擎执行查询类SQL语句的流程
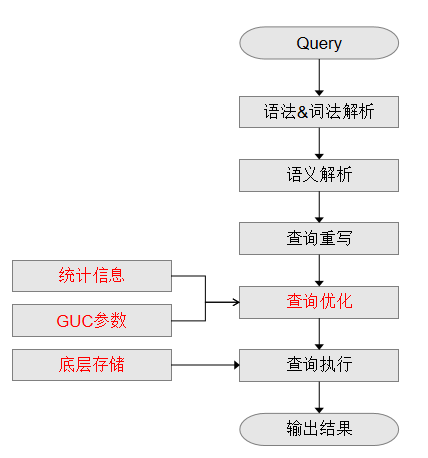
说明 1 SQL引擎执行查询类SQL语句的步骤说明
1、语法&词法解析
按照约定的SQL语句规则,把输入的SQL语句从字符串转化为格式化结构(Stmt)。
2、语义解析
将"语法&词法解析"输出的格式化结构转化为数据库可以识别的对象。
3、查询重写
根据规则把"语义解析"的输出等价转化为执行上更为优化的结构。
4、查询优化
根据"查询重写"的输出和数据库内部的统计信息规划SQL语句具体的执行方式,也就是执行计划。统计信息和GUC参数对查询优化(执行计划)的影响,请参见调优手段之统计信息和调优手段之GUC参数。
5、查询执行
根据"查询优化"规划的执行路径执行SQL查询语句。底层存储方式的选择合理性,将影响查询执行效率。详见调优手段之底层存储。
调优手段之统计信息
MogDB优化器是典型的基于代价的优化 (Cost-Based Optimization,简称CBO)。在这种优化器模型下,数据库根据表的元组数、字段宽度、NULL记录比率、distinct值、MCV值、HB值等表的特征值,以及一定的代价计算模型,计算出每一个执行步骤的不同执行方式的输出元组数和执行代价(cost),进而选出整体执行代价最小/首元组返回代价最小的执行方式进行执行。这些特征值就是统计信息。从上面描述可以看出统计信息是查询优化的核心输入,准确的统计信息将帮助规划器选择最合适的查询规划,一般来说我们通过analyze语法收集整个表或者表的若干个字段的统计信息,周期性地运行ANALYZE,或者在对表的大部分内容做了更改之后马上运行它是个好习惯。
调优手段之GUC参数
查询优化的主要目的是为查询语句选择高效的执行方式。
如下SQL语句:
select count(1)
from customer inner join store_sales on (ss_customer_sk = c_customer_sk);在执行customer inner join store_sales的时候,MogDB支持Nested Loop、Merge Join和Hash Join三种不同的Join方式。优化器会根据表customer和表store_sales的统计信息估算结果集的大小以及每种join方式的执行代价,然后对比选出执行代价最小的执行计划。
正如前面所说,执行代价计算都是基于一定的模型和统计信息进行估算,当因为某些原因代价估算不能反映真实的cost的时候,我们就需要通过guc参数设置的方式让执行计划倾向更优规划。
调优手段之底层存储
MogDB的表支持行存表、列存表,底层存储方式的选择严格依赖于客户的具体业务场景。一般来说计算型业务查询场景(以关联、聚合操作为主)建议使用列存表;点查询、大批量UPDATE/DELETE业务场景适合行存表。
对于每种存储方式还有对应的存储层优化手段,这部分会在后续的调优章节深入介绍。
调优手段之SQL重写
除了上述干预SQL引擎所生成执行计划的执行性能外,根据数据库的SQL执行机制以及大量的实践发现,有些场景下,在保证客户业务SQL逻辑等价(或不变)的前提下,通过一定规则由DBA重写SQL语句,可以大幅度的提升SQL语句的性能。
这种调优场景对DBA的要求比较高,需要对客户业务有足够的了解,同时也需要扎实的SQL语句基本功,后续会介绍几个常见的SQL改写场景。