Data Imported into a Time-Series Table from Kafka
Sensor or monitoring data can be imported into a time-series table from Kafka. Kafka is connected to Uqbar using a Kafka JDBC connector. The connector is used for reading data from Kafka, sending SQLs in a message to Uqbar for execution, recording the failure result, and keeping the message position. Data should be inserted into a database in batches.

Installation Process
Download Kafka
Access Kafka official website to download a Kafka software package and then decompress it.
Download a Database Connector
Download a JDBC driver corresponding to the target database, such as openGauss. Access openGauss official website to download a JDBC driver corresponding to the target operating system.
After the download is finished, decompress it to obtain a JAR package.
Copy the JAR package to the kafka path, such as /kafka_2.12-3.2.1/libs.
Download a Kafka JDBC Connector
Access https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc?_ga=2.140576818.1269349503.1660542741-1354758524.1659497119 and then click Download to obtain the Kafka JDBC Connector.
After the download is finished, decompress it to any directory for later use.
Modify Configuration Files
server.properties
Edit the config/server.properties file in the kafka directory, such as kafka_2.12-3.2.1.
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://your.host.name:9092Add listeners=PLAINTEXT://0.0.0.0:9092 or change the original content to it. Otherwise, the requests from the external network cannot be listened.
Add advertised.listeners=PLAINTEXT://your.host.name:9092 or change the original content to it. your.host.name indicates the IP address of the local machine. Otherwise, Kafka cannot be accessed from the external network.
connect-distributed.properties
Edit the config/connect-distributed.properties file in the kafka directory, such as kafka_2.12-3.2.1.
plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2plugin.path indicates the position of the confluentinc-kafka-connect-jdbc folder, such as plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2.
Kafka Startup
-
Open a Command Prompt or terminal to access the kafka directory, such as kafka_2.12-3.2.1.
cd /usr/local/Cellar/kafka_2.12-3.2.1 -
Start Zookeeper.
sh bin/zookeeper-server-start.sh config/zookeeper.properties -
Start Kafka.
sh bin/kafka-server-start.sh config/server.properties -
Run
jpsto query the Zookeeper and Kafka status.81243 QuorumPeerMain #Zookeeper 30701 Launcher 81598 Kafka # Kafka -
Start Kafka Connect Worker.
sh bin/connect-distributed.sh config/connect-distributed.propertiesIf information similar to the following is displayed, the startup is successful.

Run
jpsto query the ConnectDistributed process. It is running.83931 ConnectDistributed -
Start JDBC Connector.
-
Method one: Start JDBC Connector.
Open a Command Prompt or terminal to start JDBC Connector.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{ "name":"connector-name", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB", "connection.user":"user", "connection.password":"password", "topics":"test_topic", "insert.mode": "insert", "table.name.format":"table_name_${topic}", "auto.create":true, "dialect.name": "PostgreSqlDatabaseDialect" } }' -
Method two: Create a JSON file to configure JDBC Connector.
Create a JSON file named
test.json, including the following content.{ "name":"connector-name", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB", "connection.user":"user", "connection.password":"password", "topics":"test_topic", "insert.mode": "insert", "table.name.format":"table_name_${topic}", "auto.create":true, "dialect.name": "PostgreSqlDatabaseDialect" } }Start Kafka in a Command Prompt or terminal.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d @test.json -
Method three: Use the Postman test tool.
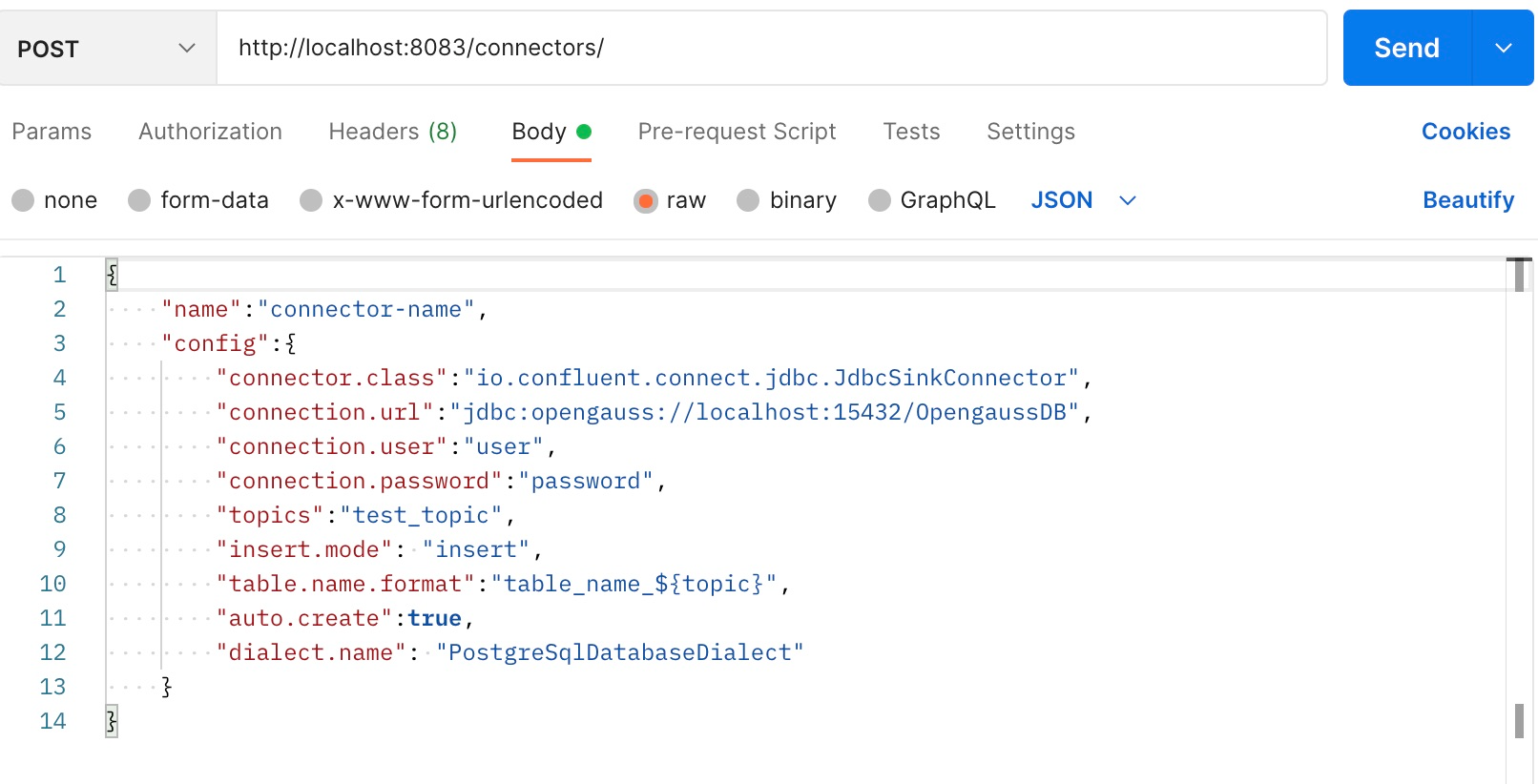
After parameters are set, send the post request.
If information similar to the following is displayed, JDBC Connector is started successfully.
{ "name": "connector-name", "config": { "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url": "jdbc:opengauss://localhost:15432/sink", "connection.user": "user1", "connection.password": "Enmo@123", "topics": "test", "insert.mode": "insert", "table.name.format": "tableName_${topic}", "auto.create": "true", "dialect.name": "PostgreSqlDatabaseDialect", "name": "connector-name" }, "tasks": [], "type": "sink" }
-
Data Write Example
A JDBC Connector needs to contain the following parameters at least.
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB",
"connection.user":"user",
"connection.password":"password",
"topics":"test",
"table.name.format":"tableName"Assume the table structure of data to be written into a database is as follows.
CREATE TABLE "test" (
"id" INT NOT NULL,
"longitude" REAL NULL,
"latitude" REAL NULL,
"temperature" REAL NULL,
"humidity" REAL NULL,
"time" TIME NULL,
"string_time" TEXT NULL,
"randomString" TEXT NULL
);curl -X POST http://localhost:8083/connectors -H "Content-Type:application/json" -d '{
"name":"connector-name",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:opengauss://localhost:15432/sink",
"connection.user":"user1",
"connection.password":"password",
"topics":"topic",
"table.name.format":"test"
}
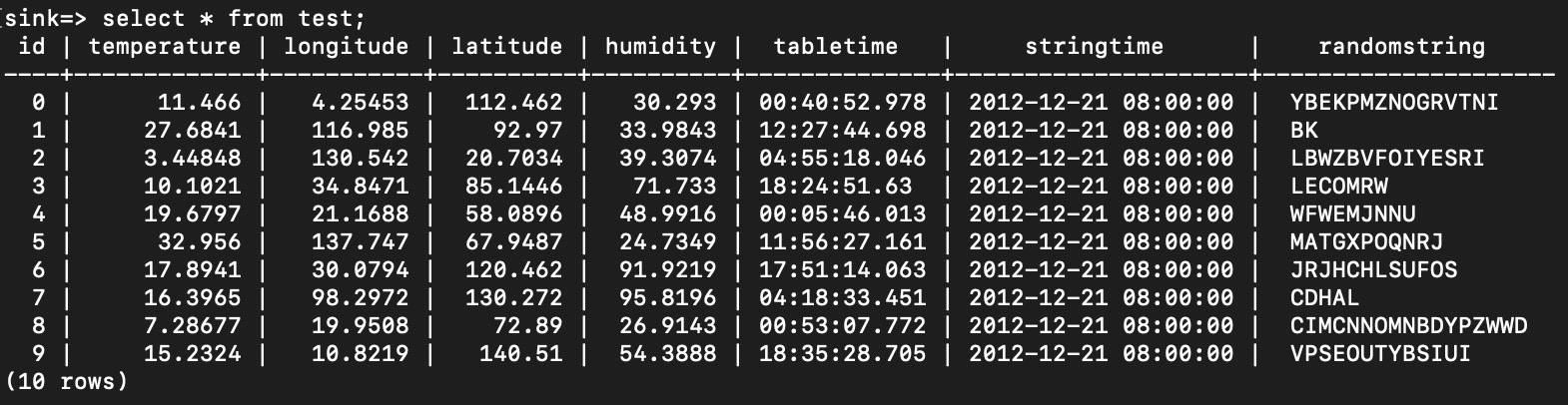
}'After sending data from the source end and starting JDBC Connector, if information similar to the following is displayed, Kafka is started successfully.

After performing the table query, you can find that data has been saved in the table.