v2.0
histogram()
功能描述
用于生成直方图/柱状图(histogram)数据来分析时间序列数据的分布情况。可以帮助理解时间序列数据的值在给定范围内的分布情况,以及发现异常值或数据倾斜。
语法格式
SELECT histogram(column,min,max,num_buckets) FROM your_table;参数说明
-
column:时序表中要生成直方图的列名。
-
min:直方图的范围的下限(包含)。
-
max:直方图的范围的上限(不包含)。
-
nbuckets:指定生成的直方图中的桶(buckets)数量。
计算直方图时,将min-max均分为nbuckets个子区间(左闭右开),小于min的值单独划分为一个区间,大于等于max的值单独划分为一个区间,实际上桶的数量为nbuckets+2。直方图的计算结果为column值落在每一个区间的数量。
histogram函数的作用:
- 分布分析:通过生成直方图,可以了解时序数据的值在给定范围内的分布情况。每个桶表示一个值范围,并计算在该范围内的数据点数量。这有助于发现数据的分布模式、峰值和异常值。
- 数据倾斜检测:直方图可以帮助识别时序数据中是否存在数据倾斜。如果某个桶的数量明显高于其他桶,表示该值范围内的数据点较多,可能存在数据倾斜或异常情况。
- 数据划分:通过将时序数据划分为多个桶,可以将数据进行粗粒度的分区或分组。这有助于更好地理解数据集的组成和分布,以及在查询和分析过程中提供更高效的聚合计算。
示例
以下示例介绍如何使用histogram函数生成直方图数据:
Uqbar=# select city, histogram(temperature, -10,30, 4) from weather group by city;
city | histogram
------------+------------------------------
chengdu | {0,30,45,55,185,50}
jinan | {20,30,40,60,175,40}
beijing | {10,20,60,70,170,35}
(3 row)该查询会对weather表中的temperature列生成6个桶的直方图数据,并按照 city 进行分组。例如查询输出的第一行展示 city = ‘chengdu’的数据的直方图,以图表的方式展示如下。
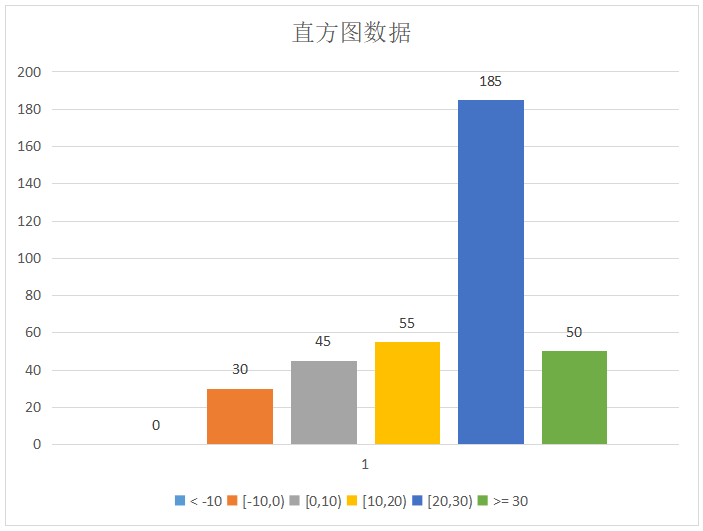
通过使用histogram函数,您可以对时序数据进行分布分析,发现异常值或数据倾斜,并在数据分析过程中提供更多见解和洞察。